
به اپلیکیشن تطبیق لباس خوش آمدید! این پروژه قدرت مدل GPT-4o را در تحلیل تصاویر لباسها و استخراج ویژگیهای کلیدی مانند رنگ، سبک و نوع نشان میدهد. هسته اصلی اپلیکیشن ما بر اساس این مدل پیشرفته تحلیل تصویر که توسط OpenAI توسعه یافته است، استوار است که به ما امکان میدهد ویژگیهای لباس ورودی را به دقت شناسایی کنیم.
با استفاده از قابلیتهای مدل GPT-4o، ما از یک الگوریتم تطبیق سفارشی و تکنیک RAG برای جستجو در پایگاه دانش خود برای آیتمهایی که با ویژگیهای شناسایی شده مطابقت دارند، استفاده میکنیم.
...

مدلهای GPT با درکی که از زبان طبیعی دارند قدرت فهم سوالات و جواب دادن به آنها را دارند. ولی اگر بخواهیم که GPT به سوالات در مورد موضوعات ناآشنا پاسخ دهد، باید چه کار کنید؟
مثالهایی از موضوعات ناآشنا:
رویدادهای اخیر پس از سپتامبر 2021 اسناد شخصی شما اطلاعات مربوط به محصولات فروشگاه شما پاسخگویی به سوالات مشتریان در مورد خدمات شرکت شما و غیره.
این notebook نشان میدهد که چگونه با استفاده از روش دو مرحلهای جستجو-پرسش، GPT را قادر به پاسخگویی به سوالات با استفاده از دیتابیس اطلاعات متنی که غالبا در حالت عادی در دسترس مدل قرار ندارد کنیم.
...

این نوتبوک نحوه ساخت یک اپلیکیشن جستجوی معنایی در آرشیوی از فیلمها را با استفاده از جستجوی برداری MongoDB Atlas نشان میدهد.
مرحله 1: تنظیم محیط # دو پیشنیاز برای ساخت این اپلیکیشن وجود دارد:
کلاستر MongoDB Atlas: برای ایجاد یک کلاستر رایگان MongoDB Atlas، ابتدا باید یک حساب کاربری MongoDB Atlas ایجاد کنید. برای این کار به وبسایت MongoDB Atlas مراجعه کرده و روی “Register” کلیک کنید. به داشبورد MongoDB Atlas بروید و کلاستر خود را تنظیم کنید.
...

استفاده از Redis به عنوان پایگاه داده وکتور # این پست مقدمهای بر استفاده از Redis به عنوان پایگاه داده وکتور است. Redis یک پایگاه داده مقیاسپذیر است که میتواند با استفاده از ماژول RediSearch به عنوان پایگاه داده وکتور استفاده شود. ماژول RediSearch به شما امکان میدهد وکتورها را در Redis ایندکس و جستجو کنید. این نوتبوک به شما نشان میدهد که چگونه از ماژول RediSearch برای ایندکس و جستجوی وکتورهایی که با استفاده از Gilas API ایجاد و در Redis ذخیره شدهاند، استفاده کنید.
...
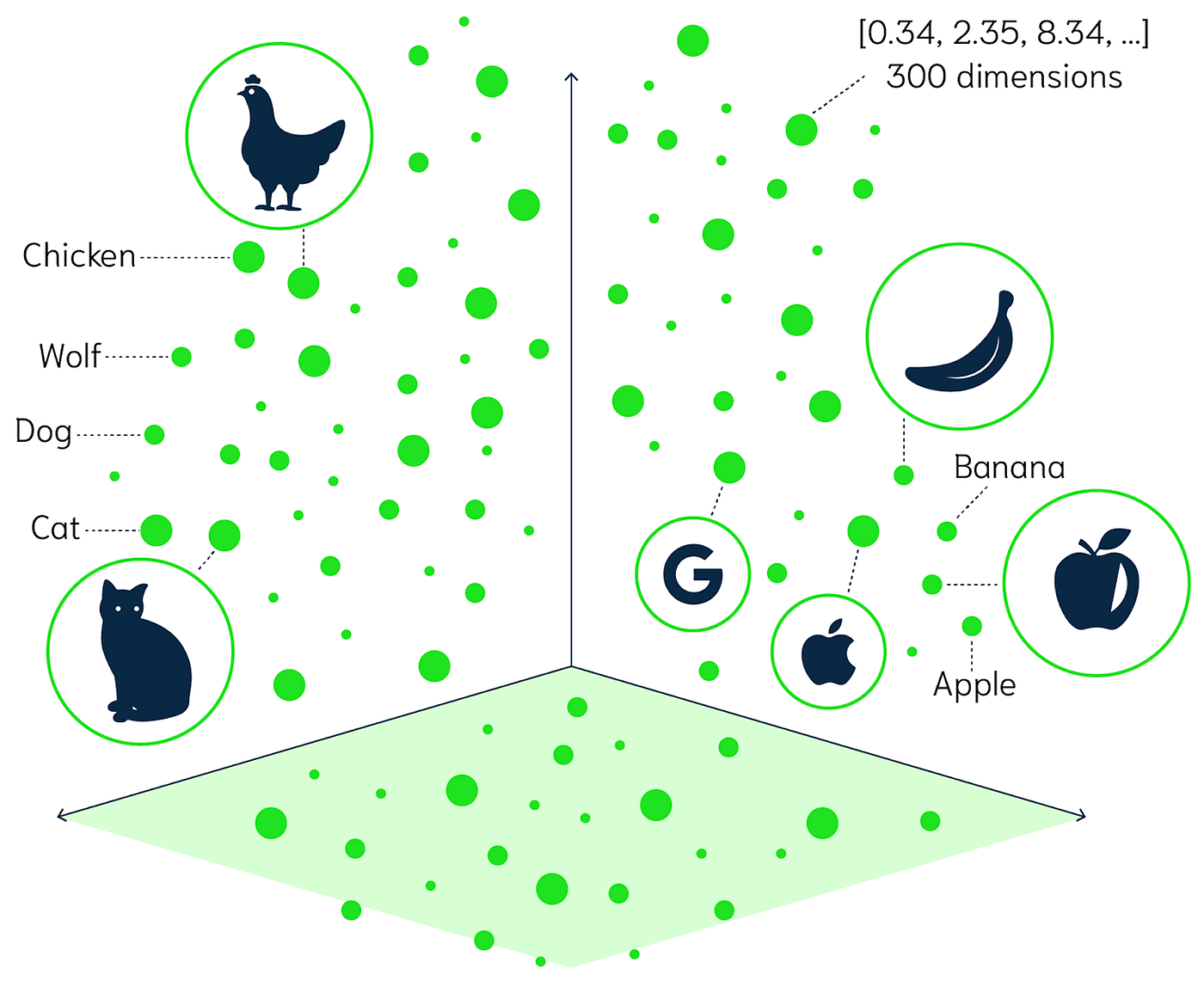
این نوتبوک نشان میدهد چگونه میتوان از embeddings برای پیادهسازی جستجوی معنایی در میان کدهای کامپیوتری استفاده کرد. برای این پست ما از کد openai-python که در گیتهاب قایل دسترسی است٬ استفاده میکنیم. سپس نسخه سادهای از تجزیه فایل و استخراج توابع از فایلهای پایتون را پیادهسازی میکنیم که میتوانند embed، index و query شوند.
توابع کمکی # برای شروع به چند تابع تجزیهی ساده برای استخراج توابع داخل کدبیس خود نیاز داریم.
...
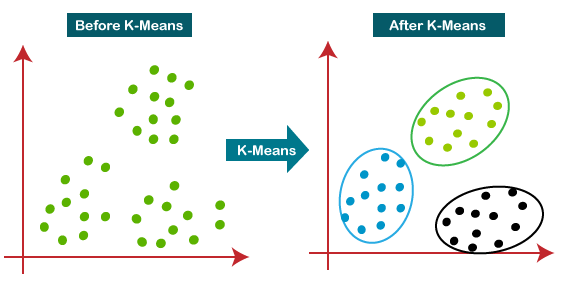
خوشهبندی K-means در پایتون با استفاده از Gilas API # ما از یک الگوریتم ساده k-means برای نشان دادن چگونگی انجام خوشهبندی استفاده میکنیم. خوشهبندی میتواند به کشف گروههای ارزشمند و پنهان در دادهها کمک کند.
جمع آوری داده ها # مجموعه دادهای که در این مثال استفاده شده است، نظرات کاربران در مورد غذاهای مختلف در آمازون میباشد. این مجموعه داده شامل 568,454 نظر در مورد غذاهای مختلف است که تا اکتبر 2012 توسط کاربران آمازون ثبت شدهاند.
...
دستهبندی با استفاده از embeddings # راههای زیادی برای دستهبندی متن وجود دارد. این نوتبوک مثالی از دستهبندی متن با استفاده از embeddings را نمایش میدهد.
در این نوتبوک امتیاز بررسی غذایی (از ۱ تا ۵) بر اساس embedding متن بررسی و پیشبینی میشود. ما دیتاست را به مجموعههای آموزشی و آزمایشی تقسیم میکنیم تا بتوانیم عملکرد مدل را بر روی دادههای دیده نشده به طور واقعی ارزیابی کنیم.
...
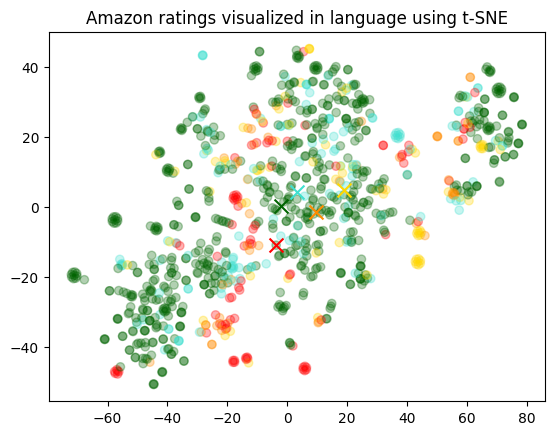
نمایش دو بعدی embeddings # ما از t-SNE برای کاهش ابعاد embeddings از ۱۵۳۶ به ۲ استفاده خواهیم کرد. پس از کاهش ابعاد به دو بعد، میتوانیم آنها را در یک نمودار پراکندگی ۲ بعدی نمایش دهیم.
جمع آوری داده ها # مجموعه دادهای که در این مثال استفاده شده است، نظرات کاربران در مورد غذاهای مختلف در آمازون میباشد. این مجموعه داده شامل 568,454 نظر در مورد غذاهای مختلف است که تا اکتبر 2012 توسط کاربران آمازون ثبت شدهاند.
...