
مدیریت متنهای طولانیتر از طول کانتکست مدل # مدلهای embedding نمیتوانند متنی که از طول کانتکست حداکثری مدل بیشتر باشد را پردازش کنند. طول حداکثری بسته به مدل متفاوت است و بر اساس توکنها اندازهگیری میشود، نه طول رشته. اگر با مفهموم توکن آشنا نیستید، به پست شمردن تعداد توکنها با tiktoken مراجعه کنید.
این notebook نشان میدهد که چگونه متنهایی که طولانیتر از طول کانتکست حداکثری مدل هستند را مدیریت کنید.
...
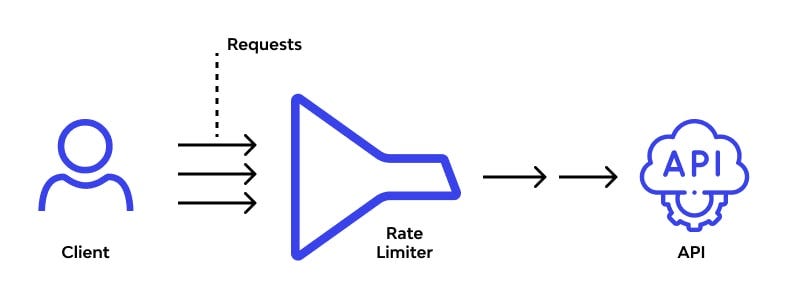
چگونه با محدودیتهای Rate limit برخورد کنیم # هنگامی که به طور مکرر Gilas API را فراخوانی میکنید، ممکن است با پیامهای خطایی مانند 429: 'Too Many Requests' یا RateLimitError مواجه شوید. این پیامهای خطا به دلیل تجاوز از محدودیتهای Rate limit رخ میدهند.
محدودیتهای Rate limit به منظور حفظ کیفیت خدمات ما برای همه کاربران است. Rate limit بر روی تعداد دفعاتی که یک کاربر میتواند در یک دوره زمانی مشخص به خدمات ما دسترسی پیدا کند، محدودیت اعمال میکند.
...
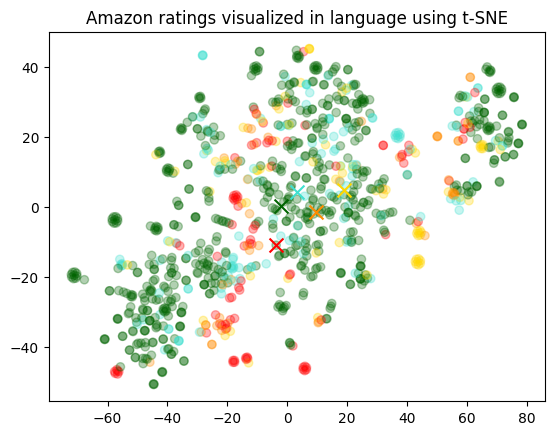
نمایش دو بعدی embeddings # ما از t-SNE برای کاهش ابعاد embeddings از ۱۵۳۶ به ۲ استفاده خواهیم کرد. پس از کاهش ابعاد به دو بعد، میتوانیم آنها را در یک نمودار پراکندگی ۲ بعدی نمایش دهیم.
جمع آوری داده ها # مجموعه دادهای که در این مثال استفاده شده است، نظرات کاربران در مورد غذاهای مختلف در آمازون میباشد. این مجموعه داده شامل 568,454 نظر در مورد غذاهای مختلف است که تا اکتبر 2012 توسط کاربران آمازون ثبت شدهاند.
...

برای انجام وظایف پیچیدهای مثل نوشتن یونیت تست برای کد پایتون بهتر است از روش پراپمت چند مرحله ای یا chain of thoughts استفاده کنیم. برخلاف یک پرامپت تکی، یک پرامپت چند مرحلهای متن را از GPT تولید کرده و سپس آن متن را به پرامپتهای بعدی میدهد.
این روش میتواند در مواردی که میخواهید GPT قبل از پاسخ دادن به موضوع فکر کند یا قبل از انجام کاری ابتدا برای آن برنامهریزی کند، مفید باشد.
...