
مدل GPT-4o (“o” به معنای “omni”) برای پردازش ترکیبی از ورودیهای متن، صوت و ویدیو طراحی شده است و میتواند خروجیهایی در قالب متن، صوت و تصویر تولید کند.
قبل از GPT-4o، کاربران میتوانستند با استفاده از حالت صوتی ChatGPT که با سه مدل جداگانه کار میکرد، تعامل داشته باشند. GPT-4o این قابلیتها را در یک مدل واحد که بر روی متن، تصویر و صوت آموزش دیده است، یکپارچه میکند. این رویکرد یکپارچه تضمین میکند که تمام ورودیها - چه متنی، تصویری یا صوتی - به صورت هماهنگ توسط همان شبکه عصبی پردازش میشوند.
قابلیتهای فعلی API #
در حال حاضر، API همانند مدل gpt-4-turbo از ورودیهای {text, image} و خروجیهای {text} پشتیبانی میکند. قابلیتهای اضافی، از جمله صوت، به زودی معرفی خواهند شد. این راهنما به شما کمک میکند تا با استفاده از GPT-4o برای درک متن، تصویر و ویدیو شروع به کدنویسی کنید.
مدل GPT-4o از طریق Gilas API در دسترس برنامهنویسان قرار دارد.
شروع به کار #
نصب OpenAI SDK برای پایتون
#
1%pip install --upgrade openai --quiet
ساخت کلاینت #
ابتدا یک کلاینت از OpenAI SDK ساخته و یک درخواست تست را به Gilas API ارسال میکنیم.
برای اجرای کدهای زیر ابتدا باید یک کلید API را از طریق پنل کاربری گیلاس تولید کنید. برای این کار ابتدا یک حساب کاربری جدید بسازید یا اگر صاحب حساب کاربری هستید وارد پنل کاربری خود شوید. سپس، به صفحه کلید API بروید و با کلیک روی دکمه “ساخت کلید API” یک کلید جدید برای دسترسی به Gilas API بسازید.
1# imports
2from openai import OpenAI # for calling the OpenAI API
3import os # for getting API token from env variable OPENAI_API_KEY
4
5client = OpenAI(
6 api_key=os.environ.get(("GILAS_API_KEY", "<کلید API خود را اینجا بسازید https://dashboard.gilas.io/apiKey>")),
7 base_url="https://api.gilas.io/v1/" # Gilas APIs
8)
9
10
11completion = client.chat.completions.create(
12 model=MODEL,
13 messages=[
14 {"role": "system", "content": "You are a helpful assistant. Help me with my math homework!"}, # <-- این پیام سیستمی است که به مدل زمینه میدهد
15 {"role": "user", "content": "Hello! Could you solve 2+2?"} # <-- این پیام کاربر است که مدل برای آن پاسخ تولید خواهد کرد
16 ]
17)
18
19print("Assistant: " + completion.choices[0].message.content)
Assistant: Of course!
\[ 2 + 2 = 4 \]
If you have any other questions, feel free to ask!
پردازش تصویر #
مدل GPT-4o میتواند تصاویر را مستقیماً پردازش کرده و اقدامات هوشمندانهای بر اساس تصویر انجام دهد. تصاویر را میتوان در دو فرمت برای مدل ارسال کرد:
- Base64 Encoded
- URL
ابتدا تصویری که استفاده خواهیم کرد را مشاهده میکنیم، سپس این تصویر را به هر دو صورت Base64 و لینک URL به API ارسال میکنیم.
1from IPython.display import Image, display, Audio, Markdown
2import base64
3
4IMAGE_PATH = "data/triangle.png"
5
6# پیشنمایش تصویر برای زمینه
7display(Image(IMAGE_PATH))
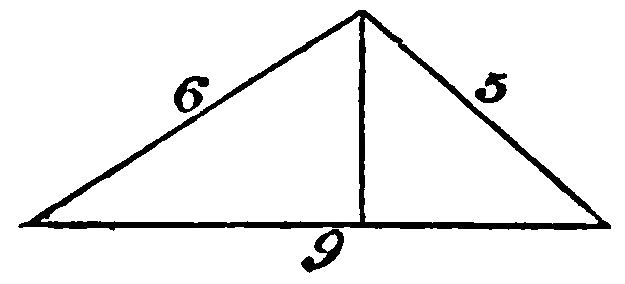
پردازش تصویر Base64 #
باز کردن فایل تصویر و کدگذاری آن به عنوان یک رشته base64:
1
2def encode_image(image_path):
3 with open(image_path, "rb") as image_file:
4 return base64.b64encode(image_file.read()).decode("utf-8")
5
6base64_image = encode_image(IMAGE_PATH)
7
8response = client.chat.completions.create(
9 model=MODEL,
10 messages=[
11 {"role": "system", "content": "You are a helpful assistant that responds in Markdown. Help me with my math homework!"},
12 {"role": "user", "content": [
13 {"type": "text", "text": "What's the area of the triangle?"},
14 {"type": "image_url", "image_url": {
15 "url": f"data:image/png;base64,{base64_image}"}
16 }
17 ]}
18 ],
19 temperature=0.0,
20)
21
22print(response.choices[0].message.content)
To find the area of the triangle, we can use Heron's formula. First, we need to find the semi-perimeter of the triangle.
The sides of the triangle are 6, 5, and 9.
1. Calculate the semi-perimeter \( s \):
\[ s = \frac{a + b + c}{2} = \frac{6 + 5 + 9}{2} = 10 \]
2. Use Heron's formula to find the area \( A \):
\[ A = \sqrt{s(s-a)(s-b)(s-c)} \]
Substitute the values:
\[ A = \sqrt{10(10-6)(10-5)(10-9)} \]
\[ A = \sqrt{10 \cdot 4 \cdot 5 \cdot 1} \]
\[ A = \sqrt{200} \]
\[ A = 10\sqrt{2} \]
So, the area of the triangle is \( 10\sqrt{2} \) square units.
پردازش تصویر URL #
همچنین شما میتوانید فایل های تصویری که به صورت آزاد بر روی اینترنت قابل دسترسی هستند را با ارسال URL در دسترس مدل قرار دهید.
1response = client.chat.completions.create(
2 model=MODEL,
3 messages=[
4 {"role": "system", "content": "You are a helpful assistant that responds in Markdown. Help me with my math homework!"},
5 {"role": "user", "content": [
6 {"type": "text", "text": "What's the area of the triangle?"},
7 {"type": "image_url", "image_url": {
8 "url": "https://upload.wikimedia.org/wikipedia/commons/e/e2/The_Algebra_of_Mohammed_Ben_Musa_-_page_82b.png"}
9 }
10 ]}
11 ],
12 temperature=0.0,
13)
14
15print(response.choices[0].message.content)
To find the area of the triangle, we can use Heron's formula. Heron's formula states that the area of a triangle with sides of length \(a\), \(b\), and \(c\) is:
\[ \text{Area} = \sqrt{s(s-a)(s-b)(s-c)} \]
where \(s\) is the semi-perimeter of the triangle:
\[ s = \frac{a + b + c}{2} \]
For the given triangle, the side lengths are \(a = 5\), \(b = 6\), and \(c = 9\).
First, calculate the semi-perimeter \(s\):
\[ s = \frac{5 + 6 + 9}{2} = \frac{20}{2} = 10 \]
Now, apply Heron's formula:
\[ \text{Area} = \sqrt{10(10-5)(10-6)(10-9)} \]
\[ \text{Area} = \sqrt{10 \cdot 5 \cdot 4 \cdot 1} \]
\[ \text{Area} = \sqrt{200} \]
\[ \text{Area} = 10\sqrt{2} \]
So, the area of the triangle is \(10\sqrt{2}\) square units.
پردازش ویدیو #
در حالی که امکان ارسال مستقیم ویدیو به API وجود ندارد، GPT-4o میتواند ویدیوها را درک کند اگر فریمها را نمونهبرداری کرده و سپس به عنوان تصاویر ارائه دهید. این مدل در این کار بهتر از GPT-4 Turbo عمل میکند.
از آنجا که GPT-4o در API هنوز از ورودی صوتی پشتیبانی نمیکند (تا ماه می 2024)، ما از ترکیب GPT-4o و Whisper برای پردازش هر دو صوت و تصویر یک ویدیو استفاده خواهیم کرد و دو مورد استفاده را نشان خواهیم داد:
- خلاصهسازی
- پرسش و پاسخ
تنظیمات برای پردازش ویدیو #
ما از دو پکیج پایتون برای پردازش ویدیو استفاده خواهیم کرد - opencv-python و moviepy.
که برای اجرا به ffmpeg نیاز دارند، بنابراین مطمئن شوید که این را قبل از آن نصب کردهاید. بسته به سیستم عامل شما، ممکن است نیاز به اجرای brew install ffmpeg یا sudo apt install ffmpeg داشته باشید.
پردازش ویدیو به دو بخش: فریمها و صوت #
1import cv2
2from moviepy.editor import VideoFileClip
3import time
4import base64
5
6# ما از ویدیوی `OpenAI DevDay` استفاده خواهیم کرد. میتوانید ویدیو را اینجا بررسی کنید: https://www.youtube.com/watch?v=h02ti0Bl6zk
7
8VIDEO_PATH = "data/keynote_recap.mp4"
1def process_video(video_path, seconds_per_frame=2):
2 base64Frames = []
3 base_video_path, _ = os.path.splitext(video_path)
4
5 video = cv2.VideoCapture(video_path)
6 total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
7 fps = video.get(cv2.CAP_PROP_FPS)
8 frames_to_skip = int(fps * seconds_per_frame)
9 curr_frame=0
10
11 while curr_frame < total_frames - 1:
12 video.set(cv2.CAP_PROP_POS_FRAMES, curr_frame)
13 success, frame = video.read()
14 if not success:
15 break
16 _, buffer = cv2.imencode(".jpg", frame)
17 base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
18 curr_frame += frames_to_skip
19 video.release()
20
21 # استخراج صوت از ویدیو
22 audio_path = f"{base_video_path}.mp3"
23 clip = VideoFileClip(video_path)
24 clip.audio.write_audiofile(audio_path, bitrate="32k")
25 clip.audio.close()
26 clip.close()
27
28 print(f"Extracted {len(base64Frames)} frames")
29 print(f"Extracted audio to {audio_path}")
30 return base64Frames, audio_path
31
32# استخراج 1 فریم در هر ثانیه. میتوانید پارامتر `seconds_per_frame` را برای تغییر نرخ نمونهبرداری تنظیم کنید
33base64Frames, audio_path = process_video(VIDEO_PATH, seconds_per_frame=1)
MoviePy - Writing audio in data/keynote_recap.mp3
MoviePy - Done.
Extracted 218 frames
Extracted audio to data/keynote_recap.mp3
1## نمایش فریمها و صوت برای زمینه
2display_handle = display(None, display_id=True)
3for img in base64Frames:
4 display_handle.update(Image(data=base64.b64decode(img.encode("utf-8")), width=600))
5 time.sleep(0.025)
6
7Audio(audio_path)

مثال 1: خلاصهسازی #
حالا که هم فریمهای ویدیو و هم صوت را داریم، بیایید چند تست مختلف برای تولید خلاصه ویدیو انجام دهیم تا نتایج استفاده از مدلها با ورودیهای مختلف را مقایسه کنیم. انتظار داریم که خلاصهای که با استفاده از هر دو ورودی تصویری و صوتی تولید میشود، دقیقتر باشد، زیرا مدل قادر است از کل زمینه ویدیو استفاده کند.
- خلاصه تصویری
- خلاصه صوتی
- خلاصه تصویری + صوتی
خلاصه تصویری #
خلاصه تصویری با ارسال تنها فریمهای ویدیو به مدل تولید میشود. با تنها فریمها، مدل احتمالاً جنبههای بصری را درک میکند، اما جزئیات بحث شده توسط سخنران را از دست میدهد.
1response = client.chat.completions.create(
2 model=MODEL,
3 messages=[
4 {"role": "system", "content": "You are generating a video summary. Please provide a summary of the video. Respond in Markdown."},
5 {"role": "user", "content": [
6 "These are the frames from the video.",
7 *map(lambda x: {"type": "image_url",
8 "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames)
9 ],
10 }
11 ],
12 temperature=0,
13)
14print(response.choices[0].message.content)
## Video Summary: OpenAI DevDay Keynote Recap
The video appears to be a keynote recap from OpenAI's DevDay event. Here are the key points covered in the video:
1. **Introduction and Event Overview**:
- The video starts with the title "OpenAI DevDay" and transitions to "Keynote Recap."
- The event venue is shown, with attendees gathering and the stage set up.
2. **Keynote Presentation**:
- A speaker, presumably from OpenAI, takes the stage to present.
- The presentation covers various topics related to OpenAI's latest developments and announcements.
3. **Announcements**:
- **GPT-4 Turbo**: Introduction of GPT-4 Turbo, highlighting its enhanced capabilities and performance.
- **JSON Mode**: A new feature that allows for structured data output in JSON format.
- **Function Calling**: Demonstration of improved function calling capabilities, making interactions more efficient.
- **Context Length and Control**: Enhancements in context length and user control over the model's responses.
- **Better Knowledge Integration**: Improvements in the model's knowledge base and retrieval capabilities.
4. **Product Demonstrations**:
- **DALL-E 3**: Introduction of DALL-E 3 for advanced image generation.
- **Custom Models**: Announcement of custom models, allowing users to tailor models to specific needs.
- **API Enhancements**: Updates to the API, including threading, retrieval, and code interpreter functionalities.
5. **Pricing and Token Efficiency**:
- Discussion on GPT-4 Turbo pricing, emphasizing cost efficiency with reduced input and output tokens.
6. **New Features and Tools**:
- Introduction of new tools and features for developers, including a variety of GPT-powered applications.
- Emphasis on building with natural language and the ease of creating custom applications.
7. **Closing Remarks**:
- The speaker concludes the presentation, thanking the audience and highlighting the future of OpenAI's developments.
The video ends with the OpenAI logo and the event title "OpenAI DevDay."
همانطور که انتظار میرفت - مدل قادر است جنبههای کلی ویدیو را درک کند، اما جزئیات ارائه شده در سخنرانی را از دست میدهد.
خلاصه صوتی #
خلاصه صوتی با ارسال متن صوتی به مدل تولید میشود. با صرفا استفاده گردن از محتوای صوت، مدل احتمالاً به محتوای صوتی متمایل میشود و موضوعات ارائه شده توسط پاورپوینت و تصاویر را از دست میدهد.
ورودی {audio} برای GPT-4o در حال حاضر در دسترس نیست اما به زودی ارائه خواهد شد! در حال حاضر، ما از مدل whisper-1 برای پردازش صوت استفاده میکنیم.
1transcription = client.audio.transcriptions.create(
2 model="whisper-1",
3 file=open(audio_path, "rb"),
4)
5## OPTIONAL: Uncomment the line below to print the transcription
6#print("Transcript: ", transcription.text + "\n\n")
7
8response = client.chat.completions.create(
9 model=MODEL,
10 messages=[
11 {"role": "system", "content":"""You are generating a transcript summary. Create a summary of the provided transcription. Respond in Markdown."""},
12 {"role": "user", "content": [
13 {"type": "text", "text": f"The audio transcription is: {transcription.text}"}
14 ],
15 }
16 ],
17 temperature=0,
18)
19print(response.choices[0].message.content)
### Summary
Welcome to OpenAI's first-ever Dev Day. Key announcements include:
- **GPT-4 Turbo**: A new model supporting up to 128,000 tokens of context, featuring JSON mode for valid JSON responses, improved instruction following, and better knowledge retrieval from external documents or databases. It is also significantly cheaper than GPT-4.
- **New Features**:
- **Dolly 3**, **GPT-4 Turbo with Vision**, and a new **Text-to-Speech model** are now available in the API.
- **Custom Models**: A program where OpenAI researchers help companies create custom models tailored to their specific use cases.
- **Increased Rate Limits**: Doubling tokens per minute for established GPT-4 customers and allowing requests for further rate limit changes.
- **GPTs**: Tailored versions of ChatGPT for specific purposes, programmable through conversation, with options for private or public sharing, and a forthcoming GPT Store.
- **Assistance API**: Includes persistent threads, built-in retrieval, a code interpreter, and improved function calling.
OpenAI is excited about the future of AI integration and looks forward to seeing what users will create with these new tools. The event concludes with an invitation to return next year for more advancements.
همانطور که میبینیم خلاصه صوتی به محتوای بحث شده در سخنرانی تمایل دارد، اما با ساختار کمتری نسبت به خلاصه ویدیو ارائه میشود.
خلاصه تصویری + صوتی #
خلاصه تصویری + صوتی با ارسال هر دو ورودی تصویری و صوتی از ویدیو به مدل تولیدمیشود. با ارسال هر دو این ورودیها، انتظار داریم که مدل خلاصهای دقیقتر تولید کند زیرا میتواند کل زمینه ویدیو را درک کند.
1response = client.chat.completions.create(
2 model=MODEL,
3 messages=[
4 {"role": "system", "content":"""You are generating a video summary. Create a summary of the provided video and its transcript. Respond in Markdown"""},
5 {"role": "user", "content": [
6 "These are the frames from the video.",
7 *map(lambda x: {"type": "image_url",
8 "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
9 {"type": "text", "text": f"The audio transcription is: {transcription.text}"}
10 ],
11 }
12],
13 temperature=0,
14)
15print(response.choices[0].message.content)
## Video Summary: OpenAI Dev Day
### Introduction
- The video begins with the title "OpenAI Dev Day" and transitions to a keynote recap.
### Event Overview
- The event is held at a venue with a sign reading "OpenAI Dev Day."
- Attendees are seen entering and gathering in a large hall.
### Keynote Presentation
- The keynote speaker introduces the event and announces the launch of GPT-4 Turbo.
- **GPT-4 Turbo**:
- Supports up to 128,000 tokens of context.
- Introduces a new feature called JSON mode for valid JSON responses.
- Improved function calling capabilities.
- Enhanced instruction-following and knowledge retrieval from external documents or databases.
- Knowledge updated up to April 2023.
- Available in the API along with DALL-E 3, GPT-4 Turbo with Vision, and a new Text-to-Speech model.
### Custom Models
- Launch of a new program called Custom Models.
- Researchers will collaborate with companies to create custom models tailored to specific use cases.
- Higher rate limits and the ability to request changes to rate limits and quotas directly in API settings.
### Pricing and Performance
- **GPT-4 Turbo**:
- 3x cheaper for prompt tokens and 2x cheaper for completion tokens compared to GPT-4.
- Doubling the tokens per minute for established GPT-4 customers.
### Introduction of GPTs
- **GPTs**:
- Tailored versions of ChatGPT for specific purposes.
- Combine instructions, expanded knowledge, and actions for better performance and control.
- Can be created without coding, through conversation.
- Options to make GPTs private, share publicly, or create for company use in ChatGPT Enterprise.
- Announcement of the upcoming GPT Store.
### Assistance API
- **Assistance API**:
- Includes persistent threads for handling long conversation history.
- Built-in retrieval and code interpreter with a working Python interpreter in a sandbox environment.
- Improved function calling.
### Conclusion
- The speaker emphasizes the potential of integrating intelligence everywhere, providing "superpowers on demand."
- Encourages attendees to return next year, hinting at even more advanced developments.
- The event concludes with thanks to the attendees.
### Closing
- The video ends with the OpenAI logo and a final thank you message.
پس از ترکیب هر دو ورودی تصویری و صوتی، ما قادر به دریافت خلاصهای بسیار دقیقتر و جامعتر از رویداد هستیم که از اطلاعات هر دو عنصر بصری و صوتی ویدیو استفاده میکند.
مثال 2: پرسش و پاسخ #
برای پرسش و پاسخ، از همان مفهوم قبلی استفاده میکنیم تا سوالاتی از ویدیوی پردازش شده بپرسیم و همان سه تست را انجام دهیم تا مزایای ترکیب ورودیهای مختلف را نشان دهیم:
- پرسش و پاسخ تصویری
- پرسش و پاسخ صوتی
- پرسش و پاسخ تصویری + صوتی
1QUESTION = "Question: Why did Sam Altman have an example about raising windows and turning the radio on?"
1qa_visual_response = client.chat.completions.create(
2 model=MODEL,
3 messages=[
4 {"role": "system", "content": "Use the video to answer the provided question. Respond in Markdown."},
5 {"role": "user", "content": [
6 "These are the frames from the video.",
7 *map(lambda x: {"type": "image_url", "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
8 QUESTION
9 ],
10 }
11 ],
12 temperature=0,
13)
14print("Visual QA:\n" + qa_visual_response.choices[0].message.content)
Visual QA:
Sam Altman used the example about raising windows and turning the radio on to demonstrate the function calling capability of GPT-4 Turbo. The example illustrated how the model can interpret and execute multiple commands in a more structured and efficient manner. The "before" and "after" comparison showed how the model can now directly call functions like `raise_windows()` and `radio_on()` based on natural language instructions, showcasing improved control and functionality.
1qa_audio_response = client.chat.completions.create(
2 model=MODEL,
3 messages=[
4 {"role": "system", "content":"""Use the transcription to answer the provided question. Respond in Markdown."""},
5 {"role": "user", "content": f"The audio transcription is: {transcription.text}. \n\n {QUESTION}"},
6 ],
7 temperature=0,
8)
9print("Audio QA:\n" + qa_audio_response.choices[0].message.content)
Audio QA:
The provided transcription does not include any mention of Sam Altman or an example about raising windows and turning the radio on. Therefore, I cannot provide an answer based on the given transcription.
1qa_both_response = client.chat.completions.create(
2 model=MODEL,
3 messages=[
4 {"role": "system", "content":"""Use the video and transcription to answer the provided question."""},
5 {"role": "user", "content": [
6 "These are the frames from the video.",
7 *map(lambda x: {"type": "image_url",
8 "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
9 {"type": "text", "text": f"The audio transcription is: {transcription.text}"},
10 QUESTION
11 ],
12 }
13 ],
14 temperature=0,
15)
16print("Both QA:\n" + qa_both_response.choices[0].message.content)
Both QA:
Sam Altman used the example of raising windows and turning the radio on to demonstrate the improved function calling capabilities of GPT-4 Turbo. The example illustrated how the model can now handle multiple function calls more effectively and follow instructions better. In the "before" scenario, the model had to be prompted separately for each action, whereas in the "after" scenario, the model could handle both actions in a single prompt, showcasing its enhanced ability to manage and execute multiple tasks simultaneously.
مقایسه سه پاسخ، دقیقترین پاسخ با استفاده از هر دو ورودی تصویری و صوتی از ویدیو تولید میشود. Sam Altman در طول سخنرانی کلیدی به طور مستقیم به بالا بردن پنجرهها یا روشن کردن رادیو اشاره نکرد، اما بهبود قابلیت مدل برای اجرای چندین تابع در یک درخواست را نشان داد در حالی که مثالها در پشت او نمایش داده میشدند.
نتیجهگیری #
ترکیب ورودیهای مختلف مانند صوت، تصویر و متن به طور قابل توجهی عملکرد مدل را در طیف گستردهای از وظایف بهبود میبخشد. این رویکرد چندوجهی امکان درک و تعامل جامعتر را فراهم میکند و به نحوی که انسانها اطلاعات را درک و پردازش میکنند، نزدیکتر میشود.
در حال حاضر، GPT-4o در Gilas API از ورودیهای متن و تصویر پشتیبانی میکند و قابلیتهای صوتی به زودی ارائه خواهند شد.