ارزیابی RAG با LlamaIndex #
در این پست به ساخت یک پایپلاین RAG و ارزیابی آن با LlamaIndex میپردازیم. این پست شامل سه بخش زیر است:
- درک
Retrieval Augmented Generation (RAG). - ساخت
RAGباLlamaIndex. - ارزیابی
RAGباLlamaIndex.
Retrieval Augmented Generation (RAG)
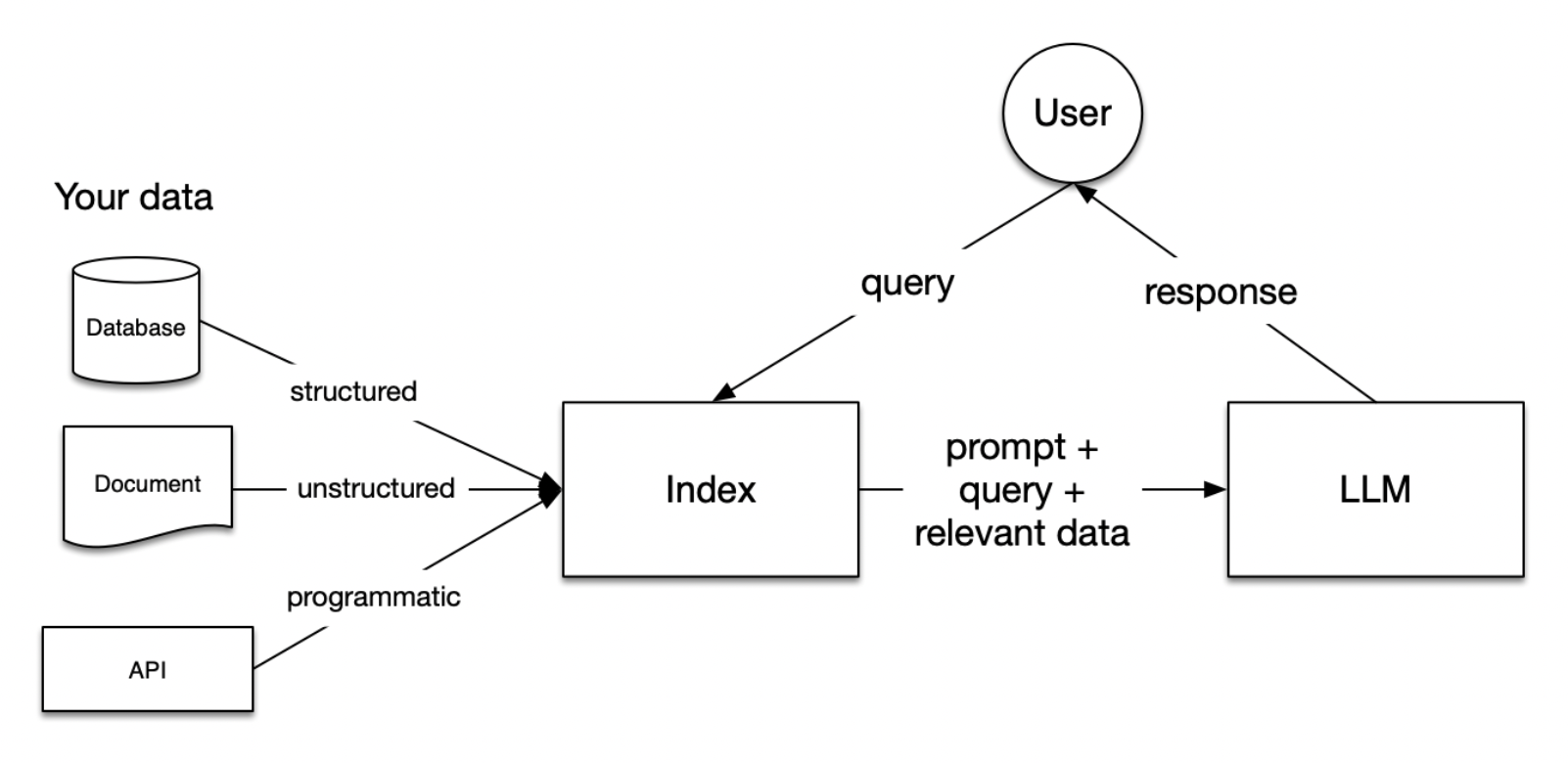
مدلهای زبانی بزرگ (LLMs) بر روی دیتاستهای وسیعی آموزش دیدهاند، اما این دیتاستها شامل دادههای محرمانه یا شخصی شما نیستند. RAG این مشکل را با ادغام دینامیک دادههای شما در طول فرآیند تولید حل میکند. این کار نه با تغییر دادههای آموزشی LLMs، بلکه با اجازه دادن به مدل برای دسترسی و استفاده لحظهای از دادههای شما برای ارائه پاسخهای متناسب و مرتبط انجام میشود.
در RAG، دادههای شما بارگذاری و برای پرس و جوها آماده میشوند یا “ایندکس” میشوند. پرس و جوهای کاربر بر روی ایندکس عمل میکنند که دادههای شما را به مرتبطترین زمینهها فیلتر کند. این زمینه و پرس و جوی شما سپس به LLM همراه با یک پراپمت ارسال میشود و LLM پاسخ پرس و جو را با استفاده از بخش های بازیابی شده از اطلاعات شما میدهد.
اگر در حال ساخت یک چتبات هستید، باید تکنیکهای RAG را برای وارد کردن دادهها به برنامه خود بدانید.
مراحل درون RAG
پنج مرحله کلیدی در RAG وجود دارد که به عنوان بخشی از هر برنامه بزرگتری که شما ایجاد میکنید، خواهند بود. این مراحل عبارتند از:
بارگذاری: به گرفتن دادههایتان از جایی که ذخیره شدهاند - فایلهای متنی، PDF، یک وبسایت دیگر، یک پایگاه داده یا یک API - و وارد کردن آن به پایپلاینتان اشاره دارد. LlamaHub صدها connector را برای انتخاب ارائه میدهد.
ایندکسگذاری: به معنای ایجاد یک ساختار داده است که امکان پرس و جو از دادهها را فراهم میکند. برای LLMs این تقریباً همیشه به معنای ایجاد vector embeddings، نمایشهای عددی دادههای شما، و همچنین استراتژیهای متادیتای متعدد دیگر برای یافتن دقیق دادههای مرتبط با زمینهی موجود در پرس و جو است.
ذخیرهسازی: پس از ایندکسگذاری دادههایتان، میخواهید ایندکس خود را همراه با هر متادیتای دیگر ذخیره کنید تا نیازی به ایندکسگذاری مجدد آن نباشد.
پرس و جو: برای هر استراتژی ایندکسگذاری، راههای زیادی برای استفاده از LLMs و ساختارهای داده LlamaIndex برای پرس و جو وجود دارد، از جمله زیر پرس و جوها، پرس و جوهای چند مرحلهای و استراتژیهای هیبریدی.
ارزیابی: یک مرحله حیاتی در هر پایپلاین بررسی میزان اثربخشی آن نسبت به استراتژیهای دیگر یا هنگام ایجاد تغییرات است. ارزیابی معیارهای عینی از دقت، صحت و سرعت پاسخهای شما به پرس و جوها ارائه میدهد.
ساخت سیستم RAG
#
حال که اهمیت سیستم RAG را درک کردیم، بیایید یک پایپلاین ساده RAG بسازیم.
1!pip install llama-index
1import nest_asyncio
2
3nest_asyncio.apply()
4
5from llama_index.evaluation import generate_question_context_pairs
6from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
7from llama_index.node_parser import SimpleNodeParser
8from llama_index.evaluation import generate_question_context_pairs
9from llama_index.evaluation import RetrieverEvaluator
10from llama_index.llms import OpenAI
11
12import os
13import pandas as pd
بیایید از متن مقاله پل گراهام برای ساخت پایپلاین RAG استفاده کنیم.
دانلود دادهها #
1!mkdir -p 'data/paul_graham/'
2!curl 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt' -o 'data/paul_graham/paul_graham_essay.txt'
بارگذاری دادهها و ساخت ایندکس #
برای اجرای کدهای زیر ابتدا باید یک کلید API را از طریق پنل کاربری گیلاس تولید کنید. برای این کار ابتدا یک حساب کاربری جدید بسازید یا اگر صاحب حساب کاربری هستید وارد پنل کاربری خود شوید. سپس، به صفحه کلید API بروید و با کلیک روی دکمه “ساخت کلید API” یک کلید جدید برای دسترسی به Gilas API بسازید.
1documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
2
3# تعریف یک LLM
4llm = OpenAI(
5 api_base="https://api.gilas.io/v1/",
6 api_key=os.environ.get("GILAS_API_KEY", "<کلید API خود را اینجا بسازید https://dashboard.gilas.io/apiKey>"),
7 model="gpt-4o")
8
9# ساخت ایندکس با اندازه chunk 512
10node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
11nodes = node_parser.get_nodes_from_documents(documents)
12vector_index = VectorStoreIndex(nodes)
ساخت یک QueryEngine و شروع به پرس و جو.
1query_engine = vector_index.as_query_engine()
1response_vector = query_engine.query("What did the author do growing up?")
بررسی پاسخ.
1response_vector.response
'The author wrote short stories and worked on programming, specifically on an IBM 1401 computer using an early version of Fortran.'
به طور پیشفرض، پایپلاین دو نود/چانک مشابه را بازیابی میکند. میتوانید این مقدار را در vector_index.as_query_engine(similarity_top_k=k) تغییر دهید.
بیایید متن هر یک از این نودهای بازیابی شده را بررسی کنیم.
'What I Worked On\n\nFebruary 2021\n\nBefore college the two main things I worked on, outside of school, were writing and programming. I didn\'t write essays. I wrote what beginning writers were supposed to write then, and probably still are: short stories. My stories were awful. They had hardly any plot, just characters with strong feelings, which I imagined made them deep.\n\nThe first programs I tried writing were on the IBM 1401 that our school district used for what was then called "data processing." This was in 9th grade, so I was 13 or 14. The school district\'s 1401 happened to be in the basement of our junior high school, and my friend Rich Draves and I got permission to use it. It was like a mini Bond villain\'s lair down there, with all these alien-looking machines — CPU, disk drives, printer, card reader — sitting up on a raised floor under bright fluorescent lights.\n\nThe language we used was an early version of Fortran. You had to type programs on punch cards, then stack them in the card reader and press a button to load the program into memory and run it. The result would ordinarily be to print something on the spectacularly loud printer.\n\nI was puzzled by the 1401. I couldn\'t figure out what to do with it. And in retrospect there\'s not much I could have done with it. The only form of input to programs was data stored on punched cards, and I didn\'t have any data stored on punched cards. The only other option was to do things that didn\'t rely on any input, like calculate approximations of pi, but I didn\'t know enough math to do anything interesting of that type. So I\'m not surprised I can\'t remember any programs I wrote, because they can\'t have done much. My clearest memory is of the moment I learned it was possible for programs not to terminate, when one of mine didn\'t. On a machine without time-sharing, this was a social as well as a technical error, as the data center manager\'s expression made clear.\n\nWith microcomputers, everything changed.'
"It felt like I was doing life right. I remember that because I was slightly dismayed at how novel it felt. The good news is that I had more moments like this over the next few years.\n\nIn the summer of 2016 we moved to England. We wanted our kids to see what it was like living in another country, and since I was a British citizen by birth, that seemed the obvious choice. We only meant to stay for a year, but we liked it so much that we still live there. So most of Bel was written in England.\n\nIn the fall of 2019, Bel was finally finished. Like McCarthy's original Lisp, it's a spec rather than an implementation, although like McCarthy's Lisp it's a spec expressed as code.\n\nNow that I could write essays again, I wrote a bunch about topics I'd had stacked up. I kept writing essays through 2020, but I also started to think about other things I could work on. How should I choose what to do? Well, how had I chosen what to work on in the past? I wrote an essay for myself to answer that question, and I was surprised how long and messy the answer turned out to be. If this surprised me, who'd lived it, then I thought perhaps it would be interesting to other people, and encouraging to those with similarly messy lives. So I wrote a more detailed version for others to read, and this is the last sentence of it.\n\n\n\n\n\n\n\n\n\nNotes\n\n[1] My experience skipped a step in the evolution of computers: time-sharing machines with interactive OSes. I went straight from batch processing to microcomputers, which made microcomputers seem all the more exciting.\n\n[2] Italian words for abstract concepts can nearly always be predicted from their English cognates (except for occasional traps like polluzione). It's the everyday words that differ. So if you string together a lot of abstract concepts with a few simple verbs, you can make a little Italian go a long way.\n\n[3] I lived at Piazza San Felice 4, so my walk to the Accademia went straight down the spine of old Florence: past the Pitti, across the bridge, past Orsanmichele, between the Duomo and the Baptistery, and then up Via Ricasoli to Piazza San Marco."
ما یک پایپلاین RAG ساختهایم و اکنون نیاز به ارزیابی عملکرد آن داریم. میتوانیم سیستم RAG/موتور پرس و جوی خود را با استفاده از ماژولهای ارزیابی اصلی LlamaIndex ارزیابی کنیم. بیایید بررسی کنیم که چگونه میتوان از این ابزارها برای اندازهگیری کیفیت سیستم تولید با افزوده بازیابی استفاده کرد.
ارزیابی #
ارزیابی باید به عنوان معیار اصلی برای بررسی برنامه RAG شما عمل کند. این ارزیابی تعیین میکند که آیا پایپلاین پاسخهای دقیقی بر اساس منابع داده و مجموعهای از پرس و جوها تولید میکند یا خیر.
در حالی که بررسی پرس و جوها و پاسخهای فردی در ابتدا مفید است، این رویکرد ممکن است با افزایش حجم نمونه ها غیرعملی شود. در عوض، ممکن است موثرتر باشد که مجموعهای از معیارهای خلاصه یا ارزیابیهای خودکار را ایجاد کنید. این ابزارها میتوانند اطلاعاتی در مورد عملکرد کلی سیستم ارائه دهند و نشان دهند که کدام بخشها نیاز به بررسی دقیقتر دارند.
در یک سیستم RAG، ارزیابی بر دو جنبه حیاتی تمرکز دارد:
- ارزیابی بازیابی: این ارزیابی دقت و مرتبط بودن اطلاعات بازیابی شده توسط سیستم را اندازهگیری میکند.
- ارزیابی پاسخ: این ارزیابی کیفیت و مناسب بودن پاسخهای تولید شده توسط سیستم بر اساس اطلاعات بازیابی شده را اندازهگیری میکند.
تولید جفتهای پرسش-زمینه: #
برای ارزیابی یک سیستم RAG، ضروری است که پرس و جوهایی داشته باشید که بتوانند زمینه صحیح را بازیابی کرده و سپس پاسخ مناسبی تولید کنند. LlamaIndex یک ماژول generate_question_context_pairs ارائه میدهد که به طور خاص برای ساخت پرسشها و جفتهای زمینه طراحی شده است که میتوانند در ارزیابی سیستم RAG برای ارزیابی بازیابی و ارزیابی پاسخ استفاده شوند. برای جزئیات بیشتر در مورد تولید پرسش، لطفاً به مستندات مراجعه کنید.
ارزیابی بازیابی: #
اکنون آمادهایم تا ارزیابیهای بازیابی خود را انجام دهیم. ما RetrieverEvaluator خود را با استفاده از دیتاست ارزیابی تولید شده اجرا خواهیم کرد.
ابتدا Retriever را ایجاد میکنیم و سپس دو تابع تعریف میکنیم: get_eval_results که retriever را بر روی دیتاست اجرا میکند و display_results که نتایج ارزیابی را نمایش میدهد.
بیایید retriever را ایجاد کنیم.
1retriever = vector_index.as_retriever(similarity_top_k=2)
تعریف RetrieverEvaluator. ما از معیارهای Hit Rate و MRR برای ارزیابی Retriever استفاده میکنیم.
Hit Rate:
نرخ Hit Rate محاسبه میکند که چه بخشی از پرس و جوها پاسخ صحیح را در میان top-k سند بازیابی شده در پیدا میکنند. به زبان ساده، این معیار نشان میدهد که سیستم چند بار پاسخ صحیح را پیدا کرده است.
Mean Reciprocal Rank (MRR):
برای هر پرس و جو، MRR دقت سیستم را با نگاه به رتبه بالاترین سند مرتبط ارزیابی میکند.
بیایید این معیارها را برای بررسی عملکرد retriever خود بررسی کنیم.
1retriever_evaluator = RetrieverEvaluator.from_metric_names(
2 ["mrr", "hit_rate"], retriever=retriever
3)
1eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
بیایید تابعی برای نمایش نتایج ارزیابی بازیابی در قالب جدول تعریف کنیم.
1def display_results(name, eval_results):
2 """نمایش نتایج از ارزیابی."""
3
4 metric_dicts = []
5 for eval_result in eval_results:
6 metric_dict = eval_result.metric_vals_dict
7 metric_dicts.append(metric_dict)
8
9 full_df = pd.DataFrame(metric_dicts)
10
11 hit_rate = full_df["hit_rate"].mean()
12 mrr = full_df["mrr"].mean()
13
14 metric_df = pd.DataFrame(
15 {"نام بازیابیکننده": [name], "نرخ ضربه": [hit_rate], "MRR": [mrr]}
16 )
17
18 return metric_df
1display_results("بازیابیکننده تعبیهسازی OpenAI", eval_results)
مشاهده: #
بازیابیکننده با استفاده از OpenAI Embeddings عملکردی با نرخ Hit rateمعادل 0.7586 نشان میدهد، در حالی که MRR با مقدار 0.6206 نشان میدهد که هنوز جا برای بهبود در اطمینان از اینکه نتایج مرتبطتر در بالای لیست قرار میگیرند وجود دارد. مشاهده اینکه MRR کمتر از نرخ Hit rate است نشان میدهد که نتایج بالاترین رتبه همیشه مرتبطترین نیستند. بهبود MRR میتواند شامل استفاده از rerankerها باشد که ترتیب اسناد بازیابی شده را اصلاح میکنند. برای درک عمیقتر از چگونگی بهینهسازی معیارهای بازیابی با استفاده از rerankerها، به بحث مفصل در این پست مراجعه کنید.
ارزیابی پاسخ: #
FaithfulnessEvaluator: اندازهگیری میکند که آیا پاسخ از یک موتور پرس و جو با هر یک از نودهای منبع مطابقت دارد. این روش برای اندازهگیری اینکه آیا پاسخها توهمی هستند مفید است.Relevancy Evaluator: اندازهگیری میکند که آیا پاسخ و نودهای منبع (زمینه بازیابی شده) با پرس و جو مطابقت دارند.
1queries = list(qa_dataset.queries.values())
Faithfulness Evaluator
#
بیایید با FaithfulnessEvaluator شروع کنیم.
ما از gpt-3.5-turbo برای تولید پاسخ برای یک پرس و جو و از gpt-4 برای ارزیابی استفاده خواهیم کرد.
بیایید service_context را به طور جداگانه برای gpt-3.5-turbo و gpt-4 ایجاد کنیم.
1# gpt-3.5-turbo
2gpt35 = OpenAI(temperature=0, model="gpt-3.5-turbo")
3service_context_gpt35 = ServiceContext.from_defaults(llm=gpt35)
4
5# gpt-4
6gpt4 = OpenAI(temperature=0, model="gpt-4")
7service_context_gpt4 = ServiceContext.from_defaults(llm=gpt4)
ایجاد یک QueryEngine با service_context gpt-3.5-turbo برای تولید پاسخ برای پرس و جو.
1vector_index = VectorStoreIndex(nodes, service_context = service_context_gpt35)
2query_engine = vector_index.as_query_engine()
ایجاد یک FaithfulnessEvaluator.
1from llama_index.evaluation import FaithfulnessEvaluator
2faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
بیایید یک پرس و جو را ارزیابی کنیم.
"Based on the author's experience and observations, why did he consider the AI practices during his first year of grad school as a hoax? Provide specific examples from the text to support your answer."
ابتدا پاسخ را تولید کرده و از faithfulness evaluator استفاده کنید.
1response_vector = query_engine.query(eval_query)
1# Compute faithfulness evaluation
2
3eval_result = faithfulness_gpt4.evaluate_response(response=response_vector)
1# You can check passing parameter in eval_result if it passed the evaluation.
2
3eval_result.passing
True
Relevancy Evaluator
#
معیار RelevancyEvaluator برای اندازهگیری اینکه آیا پاسخ و نودهای منبع معیار(زمینه بازیابی شده) با پرس و جو مطابقت دارند مفید است. این ارزیابی نشان میدهد که آیا پاسخ واقعاً به پرس و جو پاسخ میدهد یا خیر.
ایجاد RelevancyEvaluator برای ارزیابی مرتبط بودن با gpt-4.
1from llama_index.evaluation import RelevancyEvaluator
2
3relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)
بیایید ارزیابی مرتبط بودن را برای یکی از پرس و جوها انجام دهیم.
"Based on the author's experience and observations, why did he consider the AI practices during his first year of grad school as a hoax? Provide specific examples from the text to support your answer."
1# Generate response.
2# response_vector has response and source nodes (retrieved context)
3response_vector = query_engine.query(query)
4
5# Relevancy evaluation
6eval_result = relevancy_gpt4.evaluate_response(
7 query=query, response=response_vector
8)
True
Yes
Batch Evaluator:
#
حال که ارزیابی صحت و مرتبط بودن را به طور مستقل انجام دادهایم، LlamaIndex دارای BatchEvalRunner است که میتواند ارزیابیهای متعدد را به صورت دستهای انجام دهد.
1from llama_index.evaluation import BatchEvalRunner
2
3# بیایید 10 پرس و جوی برتر را برای ارزیابی انتخاب کنیم
4batch_eval_queries = queries[:10]
5
6# شروع `BatchEvalRunner` برای محاسبه ارزیابی صحت و مرتبط بودن.
7runner = BatchEvalRunner(
8 {"faithfulness": faithfulness_gpt4, "relevancy": relevancy_gpt4},
9 workers=8,
10)
11
12# محاسبه ارزیابی
13eval_results = await runner.aevaluate_queries(
14 query_engine, queries=batch_eval_queries
15)
1# Let's get faithfulness score
2faithfulness_score = sum(result.passing for result in eval_results['faithfulness']) / len(eval_results['faithfulness'])
3
4faithfulness_score
1.0
1# Let's get relevancy score
2
3relevancy_score = sum(result.passing for result in eval_results['relevancy']) / len(eval_results['relevancy'])
4
5relevancy_score
1.0
```
مشاهده: #
امتیاز صحت 1.0 نشان میدهد که پاسخهای تولید شده هیچ توهمی ندارند و کاملاً بر اساس زمینه بازیابی شده هستند.
امتیاز مرتبط بودن 1.0 نشان میدهد که پاسخهای تولید شده به طور پیوسته با زمینه بازیابی شده و پرس و جوها همخوانی دارند.
نتیجهگیری #
در این پست ما بررسی کردیم که چگونه میتوان یک پایپلاین RAG را با استفاده از LlamaIndex ساخت و ارزیابی کرد، با تمرکز خاص بر ارزیابی سیستم بازیابی و پاسخهای تولید شده درون پایپلاین.
LlamaIndex انواع دیگری از ماژولهای ارزیابی را نیز ارائه میدهد که میتوانید بیشتر در اینجا بررسی کنید.