خوشهبندی K-means در پایتون با استفاده از Gilas API #
ما از یک الگوریتم ساده k-means برای نشان دادن چگونگی انجام خوشهبندی استفاده میکنیم. خوشهبندی میتواند به کشف گروههای ارزشمند و پنهان در دادهها کمک کند.
جمع آوری داده ها #
مجموعه دادهای که در این مثال استفاده شده است، نظرات کاربران در مورد غذاهای مختلف در آمازون میباشد. این مجموعه داده شامل 568,454 نظر در مورد غذاهای مختلف است که تا اکتبر 2012 توسط کاربران آمازون ثبت شدهاند. ما از یک زیرمجموعه از این دادهها که شامل 1,000 نظر جدیدتر میباشد برای مقاصد آموزشی استفاده خواهیم کرد. این نظرات به زبان انگلیسی نوشته شدهاند و به طور کلی یا مثبت هستند یا منفی. هر نظر شامل ProductId، UserId، امتیاز (Score)، عنوان نظر (Summary) و متن نظر (Text) میباشد.
ما عنوان نظر و متن نظر را به یک متن ترکیبی واحد تبدیل خواهیم کرد. مدل این متن ترکیبی را encode کرده و یک وکتور تکی تولید خواهد کرد.
برای اجرای این نوتبوک، نیاز به نصب پکیجهای زیر دارید: pandas، openai، transformers، plotly، matplotlib، scikit-learn، torch (وابسته به transformers)، torchvision، و scipy.
1import pandas as pd
2import tiktoken
3
4# load & inspect dataset
5input_datapath = "data/fine_food_reviews_1k.csv" # to save space, we provide a pre-filtered dataset
6df = pd.read_csv(input_datapath, index_col=0)
7df = df[["Time", "ProductId", "UserId", "Score", "Summary", "Text"]]
8df = df.dropna()
9df["combined"] = (
10 "Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip()
11)
12df.head(2)
نمایش:
| Time | ProductId | UserId | Score | Summary | Text | combined | |
|---|---|---|---|---|---|---|---|
| 0 | 1351123200 | B003XPF9BO | A3R7JR3FMEBXQB | 5 | where does one start...and stop... with a tre... | Wanted to save some to bring to my Chicago fam... | Title: where does one start...and stop... wit... |
| 1 | 1351123200 | B003JK537S | A3JBPC3WFUT5ZP | 1 | Arrived in pieces | Not pleased at all. When I opened the box, mos... | Title: Arrived in pieces; Content: Not pleased... |
1
2embedding_model = "text-embedding-3-small"
3max_tokens = 8000 # the maximum for text-embedding-3-small is 8191
4embedding_encoding = "cl100k_base"
5
6# subsample to 1k most recent reviews and remove samples that are too long
7top_n = 1000
8df = df.sort_values("Time").tail(top_n * 2) # first cut to first 2k entries, assuming less than half will be filtered out
9df.drop("Time", axis=1, inplace=True)
10
11encoding = tiktoken.get_encoding(embedding_encoding)
12
13# omit reviews that are too long to embed
14df["n_tokens"] = df.combined.apply(lambda x: len(encoding.encode(x)))
15df = df[df.n_tokens <= max_tokens].tail(top_n)
حال از Gilas API برای تولید امبدینگ ها استفاده میکنیم.
برای اجرای کدهای زیر ابتدا باید یک کلید API را از طریق پنل کاربری گیلاس تولید کنید. برای این کار ابتدا یک حساب کاربری جدید بسازید یا اگر صاحب حساب کاربری هستید وارد پنل کاربری خود شوید. سپس، به صفحه کلید API بروید و با کلیک روی دکمه “ساخت کلید API” یک کلید جدید برای دسترسی به Gilas API بسازید.
1
2from openai import OpenAI # for calling the OpenAI API
3import os
4
5client = OpenAI(
6 api_key=os.environ.get(("GILAS_API_KEY", "<کلید API خود را اینجا بسازید https://dashboard.gilas.io/apiKey>")),
7 base_url="https://api.gilas.io/v1/" # Gilas APIs
8)
9
10def get_embedding(query)
11 query_embedding_response = client.embeddings.create(
12 model=embedding_model,
13 input=query,
14 )
15 return query_embedding_response.data[0].embedding
16
17
18# This may take a few minutes
19df["embedding"] = df.combined.apply(lambda x: get_embedding(x))
20df.to_csv("data/fine_food_reviews_with_embeddings_1k.csv")
داده های نهایی به شکل زیر میباشند:
1# imports
2import numpy as np
3import pandas as pd
4from ast import literal_eval
5
6# load data
7datafile_path = "./data/fine_food_reviews_with_embeddings_1k.csv"
8
9df = pd.read_csv(datafile_path)
10df["embedding"] = df.embedding.apply(literal_eval).apply(np.array) # convert string to numpy array
11matrix = np.vstack(df.embedding.values)
12matrix.shape
خروجی
(1000, 1536)
1. یافتن خوشهها با استفاده از K-means #
ما سادهترین استفاده از K-means را نشان میدهیم. شما میتوانید تعداد خوشههایی که بهترین تناسب را با یوزکیس شما دارند انتخاب کنید.
1from sklearn.cluster import KMeans
2
3n_clusters = 4
4
5kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42)
6kmeans.fit(matrix)
7labels = kmeans.labels_
8df["Cluster"] = labels
9
10df.groupby("Cluster").Score.mean().sort_values()
Cluster
0 4.105691
1 4.191176
2 4.215613
3 4.306590
Name: Score, dtype: float64
1from sklearn.manifold import TSNE
2import matplotlib
3import matplotlib.pyplot as plt
4
5tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200)
6vis_dims2 = tsne.fit_transform(matrix)
7
8x = [x for x, y in vis_dims2]
9y = [y for x, y in vis_dims2]
10
11for category, color in enumerate(["purple", "green", "red", "blue"]):
12 xs = np.array(x)[df.Cluster == category]
13 ys = np.array(y)[df.Cluster == category]
14 plt.scatter(xs, ys, color=color, alpha=0.3)
15
16 avg_x = xs.mean()
17 avg_y = ys.mean()
18
19 plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)
20plt.title("Clusters identified visualized in language 2d using t-SNE")
Text(0.5, 1.0, 'Clusters identified visualized in language 2d using t-SNE')
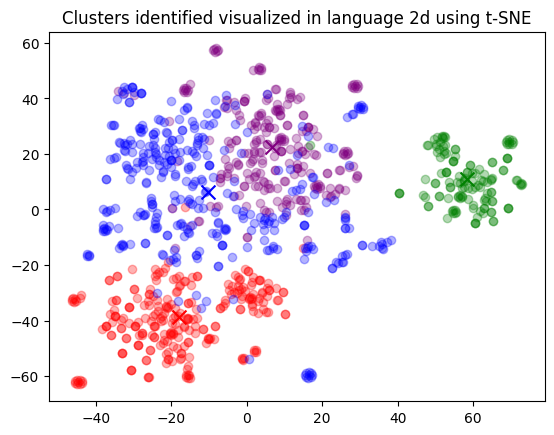
بصریسازی خوشهها در یک پروجکشن دو بعدی. در این اجرا، خوشه سبز (#1) به نظر میرسد که تفاوت زیادی با دیگران دارد. بیایید چند نمونه از هر خوشه را ببینیم.
2. نمونههای متنی در خوشهها و نامگذاری خوشهها #
بیایید نمونههای تصادفی از هر خوشه را نشان دهیم. ما از gpt-4 برای نامگذاری خوشهها بر اساس نمونه تصادفی ۵ بررسی از آن خوشه استفاده خواهیم کرد.
1
2# Reading a review which belong to each group.
3rev_per_cluster = 5
4
5for i in range(n_clusters):
6 print(f"Cluster {i} Theme:", end=" ")
7
8 reviews = "\n".join(
9 df[df.Cluster == i]
10 .combined.str.replace("Title: ", "")
11 .str.replace("\n\nContent: ", ": ")
12 .sample(rev_per_cluster, random_state=42)
13 .values
14 )
15
16 messages = [
17 {"role": "user", "content": f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:'}
18 ]
19
20 response = client.chat.completions.create(
21 model="gpt-4",
22 messages=messages,
23 temperature=0,
24 max_tokens=64,
25 top_p=1,
26 frequency_penalty=0,
27 presence_penalty=0)
28 print(response.choices[0].message.content.replace("\n", ""))
29
30 sample_cluster_rows = df[df.Cluster == i].sample(rev_per_cluster, random_state=42)
31 for j in range(rev_per_cluster):
32 print(sample_cluster_rows.Score.values[j], end=", ")
33 print(sample_cluster_rows.Summary.values[j], end=": ")
34 print(sample_cluster_rows.Text.str[:70].values[j])
35
36 print("-" * 100)
Cluster 0 Theme: The theme of these customer reviews is food products purchased on Amazon.
5, Loved these gluten free healthy bars, saved $$ ordering on Amazon: These Kind Bars are so good and healthy & gluten free. My daughter ca
1, Should advertise coconut as an ingredient more prominently: First, these should be called Mac - Coconut bars, as Coconut is the #2
5, very good!!: just like the runts<br />great flavor, def worth getting<br />I even o
5, Excellent product: After scouring every store in town for orange peels and not finding an
5, delicious: Gummi Frogs have been my favourite candy that I have ever tried. of co
----------------------------------------------------------------------------------------------------
Cluster 1 Theme: Pet food reviews
2, Messy and apparently undelicious: My cat is not a huge fan. Sure, she'll lap up the gravy, but leaves th
4, The cats like it: My 7 cats like this food but it is a little yucky for the human. Piece
5, cant get enough of it!!!: Our lil shih tzu puppy cannot get enough of it. Everytime she sees the
1, Food Caused Illness: I switched my cats over from the Blue Buffalo Wildnerness Food to this
5, My furbabies LOVE these!: Shake the container and they come running. Even my boy cat, who isn't
----------------------------------------------------------------------------------------------------
Cluster 2 Theme: All the reviews are about different types of coffee.
5, Fog Chaser Coffee: This coffee has a full body and a rich taste. The price is far below t
5, Excellent taste: This is to me a great coffee, once you try it you will enjoy it, this
4, Good, but not Wolfgang Puck good: Honestly, I have to admit that I expected a little better. That's not
5, Just My Kind of Coffee: Coffee Masters Hazelnut coffee used to be carried in a local coffee/pa
5, Rodeo Drive is Crazy Good Coffee!: Rodeo Drive is my absolute favorite and I'm ready to order more! That
----------------------------------------------------------------------------------------------------
Cluster 3 Theme: The theme of these customer reviews is food and drink products.
5, Wonderful alternative to soda pop: This is a wonderful alternative to soda pop. It's carbonated for thos
5, So convenient, for so little!: I needed two vanilla beans for the Love Goddess cake that my husbands
2, bot very cheesy: Got this about a month ago.first of all it smells horrible...it tastes
5, Delicious!: I am not a huge beer lover. I do enjoy an occasional Blue Moon (all o
3, Just ok: I bought this brand because it was all they had at Ranch 99 near us. I
----------------------------------------------------------------------------------------------------
مهم است که توجه داشته باشید که خوشهها لزوماً با آنچه شما قصد استفاده از آنها را دارید مطابقت نخواهند داشت. تعداد بیشتری از خوشهها بر الگوهای خاصتر تمرکز خواهند کرد، در حالی که تعداد کمتری از خوشهها معمولاً بر بزرگترین تفاوتها در دادهها تمرکز خواهند کرد.