دستهبندی با استفاده از embeddings #
راههای زیادی برای دستهبندی متن وجود دارد. این نوتبوک مثالی از دستهبندی متن با استفاده از embeddings را نمایش میدهد.
در این نوتبوک امتیاز بررسی غذایی (از ۱ تا ۵) بر اساس embedding متن بررسی و پیشبینی میشود. ما دیتاست را به مجموعههای آموزشی و آزمایشی تقسیم میکنیم تا بتوانیم عملکرد مدل را بر روی دادههای دیده نشده به طور واقعی ارزیابی کنیم.
جمع آوری داده ها #
مجموعه دادهای که در این مثال استفاده شده است، نظرات کاربران در مورد غذاهای مختلف در آمازون میباشد. این مجموعه داده شامل 568,454 نظر در مورد غذاهای مختلف است که تا اکتبر 2012 توسط کاربران آمازون ثبت شدهاند. ما از یک زیرمجموعه از این دادهها که شامل 1,000 نظر جدیدتر میباشد برای مقاصد آموزشی استفاده خواهیم کرد. این نظرات به زبان انگلیسی نوشته شدهاند و به طور کلی یا مثبت هستند یا منفی. هر نظر شامل ProductId، UserId، امتیاز (Score)، عنوان نظر (Summary) و متن نظر (Text) میباشد.
ما عنوان نظر و متن نظر را به یک متن ترکیبی واحد تبدیل خواهیم کرد. مدل این متن ترکیبی را encode کرده و یک وکتور تکی تولید خواهد کرد.
برای اجرای این نوتبوک، نیاز به نصب پکیجهای زیر دارید: pandas، openai، transformers، plotly، matplotlib، scikit-learn، torch (وابسته به transformers)، torchvision، و scipy.
1import pandas as pd
2import tiktoken
3
4# load & inspect dataset
5input_datapath = "data/fine_food_reviews_1k.csv" # to save space, we provide a pre-filtered dataset
6df = pd.read_csv(input_datapath, index_col=0)
7df = df[["Time", "ProductId", "UserId", "Score", "Summary", "Text"]]
8df = df.dropna()
9df["combined"] = (
10 "Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip()
11)
12df.head(2)
نمایش:
| Time | ProductId | UserId | Score | Summary | Text | combined | |
|---|---|---|---|---|---|---|---|
| 0 | 1351123200 | B003XPF9BO | A3R7JR3FMEBXQB | 5 | where does one start...and stop... with a tre... | Wanted to save some to bring to my Chicago fam... | Title: where does one start...and stop... wit... |
| 1 | 1351123200 | B003JK537S | A3JBPC3WFUT5ZP | 1 | Arrived in pieces | Not pleased at all. When I opened the box, mos... | Title: Arrived in pieces; Content: Not pleased... |
1
2embedding_model = "text-embedding-3-small"
3max_tokens = 8000 # the maximum for text-embedding-3-small is 8191
4embedding_encoding = "cl100k_base"
5
6# subsample to 1k most recent reviews and remove samples that are too long
7top_n = 1000
8df = df.sort_values("Time").tail(top_n * 2) # first cut to first 2k entries, assuming less than half will be filtered out
9df.drop("Time", axis=1, inplace=True)
10
11encoding = tiktoken.get_encoding(embedding_encoding)
12
13# omit reviews that are too long to embed
14df["n_tokens"] = df.combined.apply(lambda x: len(encoding.encode(x)))
15df = df[df.n_tokens <= max_tokens].tail(top_n)
حال از Gilas API برای تولید امبدینگ ها استفاده میکنیم.
برای اجرای کدهای زیر ابتدا باید یک کلید API را از طریق پنل کاربری گیلاس تولید کنید. برای این کار ابتدا یک حساب کاربری جدید بسازید یا اگر صاحب حساب کاربری هستید وارد پنل کاربری خود شوید. سپس، به صفحه کلید API بروید و با کلیک روی دکمه “ساخت کلید API” یک کلید جدید برای دسترسی به Gilas API بسازید.
1
2from openai import OpenAI # for calling the OpenAI API
3import os
4
5client = OpenAI(
6 api_key=os.environ.get(("GILAS_API_KEY", "<کلید API خود را اینجا بسازید https://dashboard.gilas.io/apiKey>")),
7 base_url="https://api.gilas.io/v1/" # Gilas APIs
8)
9
10def get_embedding(query)
11 query_embedding_response = client.embeddings.create(
12 model=embedding_model,
13 input=query,
14 )
15 return query_embedding_response.data[0].embedding
16
17
18# This may take a few minutes
19df["embedding"] = df.combined.apply(lambda x: get_embedding(x))
20df.to_csv("data/fine_food_reviews_with_embeddings_1k.csv")
حال که بردار امبدینگها را برای تمام نظرات تولید کردیم نگاهی به نحوه استفاده از آنها میکنیم.
1import pandas as pd
2import numpy as np
3from ast import literal_eval
4
5from sklearn.ensemble import RandomForestClassifier
6from sklearn.model_selection import train_test_split
7from sklearn.metrics import classification_report, accuracy_score
8
9datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv"
10
11df = pd.read_csv(datafile_path)
12df["embedding"] = df.embedding.apply(literal_eval).apply(np.array) # convert string to array
13
14# split data into train and test
15X_train, X_test, y_train, y_test = train_test_split(
16 list(df.embedding.values), df.Score, test_size=0.2, random_state=42
17)
18
19# train random forest classifier
20clf = RandomForestClassifier(n_estimators=100)
21clf.fit(X_train, y_train)
22preds = clf.predict(X_test)
23probas = clf.predict_proba(X_test)
24
25report = classification_report(y_test, preds)
26print(report)
precision recall f1-score support
1 0.90 0.45 0.60 20
2 1.00 0.38 0.55 8
3 1.00 0.18 0.31 11
4 0.88 0.26 0.40 27
5 0.76 1.00 0.86 134
accuracy 0.78 200
macro avg 0.91 0.45 0.54 200
weighted avg 0.81 0.78 0.73 200
میتوانیم ببینیم که مدل به خوبی توانسته است بین دستهها تمایز قائل شود. نظرات ۵ ستاره بهترین عملکرد را نشان میدهند و این امر تعجبآور نیست، زیرا این نظرات در دیتاست بیشترین تعداد را دارند.
1from utils.embeddings_utils import plot_multiclass_precision_recall
2
3plot_multiclass_precision_recall(probas, y_test, [1, 2, 3, 4, 5], clf)
RandomForestClassifier() - Average precision score over all classes: 0.90
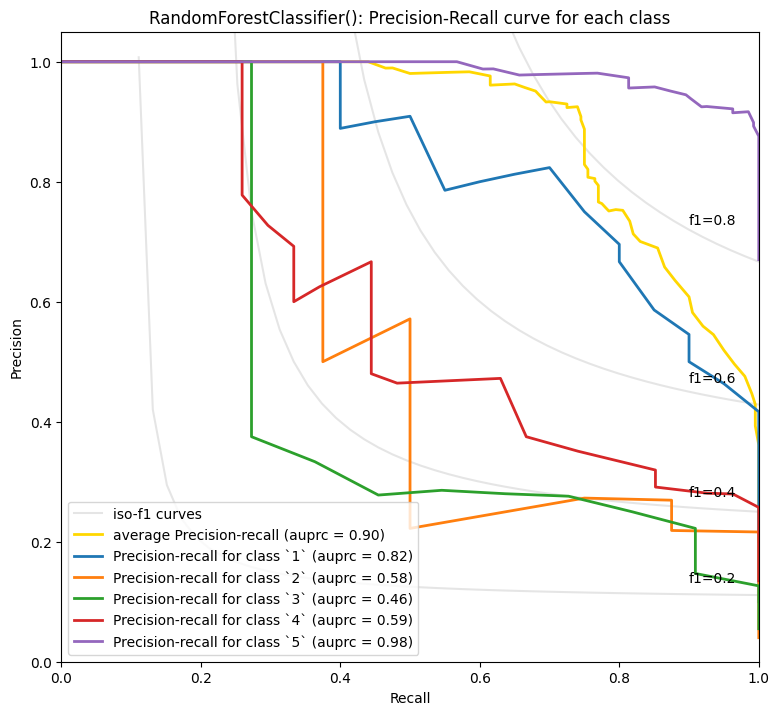
تعجبآور نیست که پیشبینی نظرات ۵ ستاره و ۱ ستاره آسانتر است. شاید با دادههای بیشتر، تفاوتهای بین ۲ تا ۴ ستاره بهتر پیشبینی شود.