
در این پست یک مثال از نحوه طراحی و پیادهسازی یک چتبات با استفاده از یک RAG را بررسی خواهیم کرد. این چتبات قادر به انجام مکالمه و به خاطر سپاری تعاملات قبلی است. در این مثال میخواهیم از قابلیت های عامل (Agent) و Chains که از طریق پکیج LangChain قابل دسترس هستند استفاده کنیم.
آماده سازی محیط #
برای این آموزش به langchain-core و langgraph نیاز خواهیم داشت:
1pip install langchain langchain-core langgraph>0.2.27 langchain_openai
یا با استفاده از Conda:
1conda install langchain langchain-core langgraph>0.2.27 langchain_openai -c conda-forge
برای جزئیات بیشتر، به مستندات راهنمای نصب مراجعه کنید.
LangSmith #
بسیاری از برنامههایی که با LangChain میسازید شامل مراحل متعددی با فراخوانیهای متعدد LLM هستند. با پیچیدهتر شدن این برنامهها، توانایی بررسی دقیق آنچه در زنجیره یا عامل (Agent) شما اتفاق میافتد بسیار مهم میشود. بهترین راه برای انجام این کار استفاده از LangSmith است.
پس از ثبتنام در لینک بالا، مطمئن شوید که متغیرهای محیطی خود را برای شروع Tracing تنظیم کردهاید:
یا، اگر در یک نوتبوک هستید، میتوانید آنها را به این صورت تنظیم کنید:
زنجیره یا chain #
ابندا به کد زیر نگاهی بیاندازید:
برای اجرای کدهای زیر ابتدا باید یک کلید API را از طریق پنل کاربری گیلاس تولید کنید. برای این کار ابتدا یک حساب کاربری جدید بسازید یا اگر صاحب حساب کاربری هستید وارد پنل کاربری خود شوید. سپس، به صفحه کلید API بروید و با کلیک روی دکمه “ساخت کلید API” یک کلید جدید برای دسترسی به Gilas API بسازید.
1from langchain_openai import ChatOpenAI
2import bs4
3from langchain.chains import create_retrieval_chain
4from langchain.chains.combine_documents import create_stuff_documents_chain
5from langchain_community.document_loaders import WebBaseLoader
6from langchain_core.prompts import ChatPromptTemplate
7from langchain_core.vectorstores import InMemoryVectorStore
8from langchain_openai import OpenAIEmbeddings
9from langchain_text_splitters import RecursiveCharacterTextSplitter
10
11
12llm = ChatOpenAI(
13 api_key="GILAS_API_KEY",
14 base_url="https://api.gilas.io/v1/",
15 model="gpt-4o-mini")
16
17# 1. Load, chunk and index the contents of the blog to create a retriever.
18loader = WebBaseLoader(
19 web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
20 bs_kwargs=dict(
21 parse_only=bs4.SoupStrainer(
22 class_=("post-content", "post-title", "post-header")
23 )
24 ),
25)
26docs = loader.load()
27
28text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
29splits = text_splitter.split_documents(docs)
30vectorstore = InMemoryVectorStore.from_documents(
31 documents=splits, embedding=OpenAIEmbeddings()
32)
33retriever = vectorstore.as_retriever()
34
35
36# 2. Incorporate the retriever into a question-answering chain.
37system_prompt = (
38 "You are an assistant for question-answering tasks. "
39 "Use the following pieces of retrieved context to answer "
40 "the question. If you don't know the answer, say that you "
41 "don't know. Use three sentences maximum and keep the "
42 "answer concise."
43 "\n\n"
44 "{context}"
45)
46
47prompt = ChatPromptTemplate.from_messages(
48 [
49 ("system", system_prompt),
50 ("human", "{input}"),
51 ]
52)
53
54question_answer_chain = create_stuff_documents_chain(llm, prompt)
55rag_chain = create_retrieval_chain(retriever, question_answer_chain)
1"Task decomposition is the process of breaking down a complicated task into smaller, more manageable steps. Techniques like Chain of Thought (CoT) and Tree of Thoughts enhance this process by guiding models to think step by step and explore multiple reasoning possibilities. This approach helps in simplifying complex tasks and provides insight into the model's reasoning."
توجه داشته باشید که ما از create_stuff_documents_chain و create_retrieval_chain استفاده کردهایم، بهطوری که اجزای اصلی راهحل ما عبارتند از:
retrieverpromptLLM
این کار فرایند افزودن تاریخچهی مکالمه را سادهتر میکند.
افزودن تاریخچهی مکالمه #
زنجیرهای که ساختهایم از ورودی پرسش بهصورت مستقیم برای بازیابی context مرتبط استفاده میکند. اما در یک محیط مکالمهای، ممکن است برای درک پرسش کاربر به پیشینهی مکالمه هم نیاز باشد. بهعنوان مثال، این مکالمه را در نظر بگیرید:
انسان: «Task Decomposition چیست؟»
هوش مصنوعی: «`Task Decomposition` به معنای تجزیه وظایف پیچیده به مراحل کوچکتر و سادهتر است تا برای یک عامل یا مدل قابل مدیریتتر شود.»
انسان: «روشهای رایج برای انجام آن چیست؟»
برای پاسخ دادن به سوال دوم، سیستم ما باید بفهمد که “آن” به Task Decomposition اشاره دارد.
برای این کار باید دو مورد را در کد موجود بهروزرسانی کنیم:
- پرامپت: پرامپت را بهروزرسانی کنیم تا از تاریخچهی پیامها بهعنوان ورودی پشتیبانی کند.
- سوالات افزودن زمینه به: اضافه کردن یک زیرزنجیره
sub-chainکه آخرین سوال کاربر را گرفته و آن را در زمینهی تاریخچهی چت بازنویسی میکند. میتوان این کار را بهسادگی بهعنوان ساختن یکretrieverآگاه به تاریخچه در نظر گرفت. در حالی که قبلاً داشتیم:
query -> retriever
حالا به این شکل تبدیل میشود:
(query, conversation history) -> LLM -> rephrased query -> retriever
مرتبطسازی سوال #
ابتدا باید یک sub-chain تعریف کنیم که پیامهای تاریخی و آخرین سوال کاربر را بگیرد و سوال را در صورتی که به اطلاعاتی در تاریخچه اشاره دارد، بازنویسی کند.
ما از پرامپتی استفاده میکنیم که شامل یک متغیر به نام MessagesPlaceholder تحت نام “chat_history” است. این کار به ما امکان میدهد که لیستی از پیامها را با استفاده از کلید ورودی chat_history به پرامپت ارسال کنیم و این پیامها بعد از پیام سیستم و قبل از پیام انسانی که حاوی آخرین سوال است، وارد میشوند.
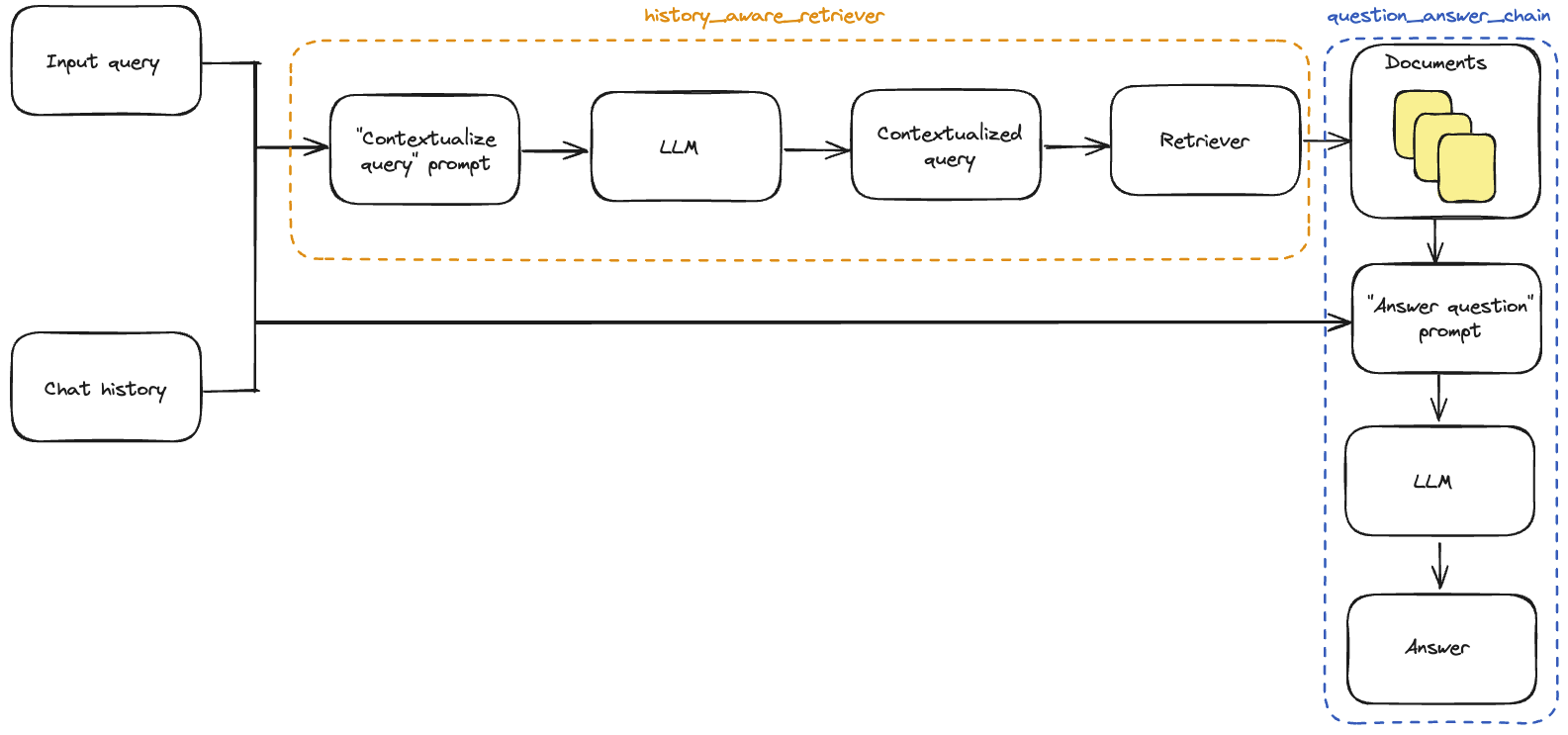
توجه داشته باشید که ما از تابع کمکی create_history_aware_retriever برای این مرحله استفاده میکنیم، که در حالتی را که chat_history خالی باشد را مدیریت میکند، و در غیر این صورت، بهطور متوالی prompt | llm | StrOutputParser() | retriever را اعمال میکند.
تابع create_history_aware_retriever زنجیرهای را میسازد که کلیدهای ورودی input و chat_history را بهعنوان ورودی میپذیرد و همان ساختار خروجی را مانند retriever دارد.
1from langchain.chains import create_history_aware_retriever
2from langchain_core.prompts import MessagesPlaceholder
3
4contextualize_q_system_prompt = (
5 "Given a chat history and the latest user question "
6 "which might reference context in the chat history, "
7 "formulate a standalone question which can be understood "
8 "without the chat history. Do NOT answer the question, "
9 "just reformulate it if needed and otherwise return it as is."
10)
11
12contextualize_q_prompt = ChatPromptTemplate.from_messages(
13 [
14 ("system", contextualize_q_system_prompt),
15 MessagesPlaceholder("chat_history"),
16 ("human", "{input}"),
17 ]
18)
19history_aware_retriever = create_history_aware_retriever(
20 llm, retriever, contextualize_q_prompt
21)
این زنجیره، بازنویسی سوال ورودی را به retriever اضافه میکند تا فرآیند بازیابی اطلاعات شامل زمینه مکالمه شود.
حالا میتوانیم زنجیره کامل پرسش و پاسخ (QA) خود را بسازیم. این کار به سادگی با بهروزرسانی retriever به history_aware_retriever جدید انجام میشود.
دوباره از create_stuff_documents_chain برای تولید یک question_answer_chain استفاده خواهیم کرد. این تابع ورودیهایی با کلیدهای context، chat_history، و input را میپذیرد و زمینه بازیابی شده را همراه با تاریخچه مکالمه و سوال ورودی میگیرد تا یک پاسخ تولید کند.
ما در نهایت زنجیره rag_chain نهایی خود را با استفاده از create_retrieval_chain میسازیم. این زنجیره، history_aware_retriever و question_answer_chain را به صورت متوالی به کار میگیرد و خروجیهای میانی مانند retrieved context را برای راحتی نگه میدارد. این تابع دارای کلیدهای ورودی input و chat_history است و شامل input، chat_history، context، و answer در خروجی خود میباشد.
1from langchain.chains import create_retrieval_chain
2from langchain.chains.combine_documents import create_stuff_documents_chain
3
4qa_prompt = ChatPromptTemplate.from_messages(
5 [
6 ("system", system_prompt),
7 MessagesPlaceholder("chat_history"),
8 ("human", "{input}"),
9 ]
10)
11
12
13question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
14
15rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
در زیر یک سؤال و یک سؤال پیگیری مطرح میکنیم که نیاز به تولید زمینه دارد تا پاسخی منطقی بازگردانده شود. به دلیل اینکه زنجیره ما شامل یک ورودی chat_history است، کلاینت باید تاریخچه چت را مدیریت کند. ما میتوانیم این کار را با افزودن پیامهای ورودی و خروجی به یک لیست انجام دهیم:
1from langchain_core.messages import AIMessage, HumanMessage
2
3chat_history = []
4
5question = "What is Task Decomposition?"
6ai_msg_1 = rag_chain.invoke({"input": question, "chat_history": chat_history})
7chat_history.extend(
8 [
9 HumanMessage(content=question),
10 AIMessage(content=ai_msg_1["answer"]),
11 ]
12)
13
14second_question = "What are common ways of doing it?"
15ai_msg_2 = rag_chain.invoke({"input": second_question, "chat_history": chat_history})
16
17print(ai_msg_2["answer"])
1Common ways of task decomposition include using simple prompting techniques, such as asking for "Steps for XYZ" or "What are the subgoals for achieving XYZ?" Additionally, task-specific instructions can be employed, like "Write a story outline" for writing tasks, or human inputs can guide the decomposition process.
ما منطق برنامهای برای ترکیب تاریخچه چت اضافه کردهایم، اما هنوز هم بهصورت دستی آن را در برنامه خود میگنجانیم. در محیط تولید، برنامه سوال و جواب معمولاً تاریخچه چت را در یک پایگاه داده ذخیره کرده و آن را به درستی خوانده و بهروزرسانی میکند.
LangGraph یک لایه ذخیرهسازی داخلی پیادهسازی میکند که آن را برای برنامههای چت که از چندین نوبت مکالمه پشتیبانی میکنند، ایدهآل میسازد.
پیچیدن مدل چت ما در یک برنامه ساده LangGraph این امکان را به ما میدهد که بهطور خودکار تاریخچه پیامها را ذخیره کنیم و توسعه برنامههای چندنوبتی را سادهتر کنیم.
LangGraph همراه با یک چکپوینتر ساده در حافظه ارائه میشود که در زیر از آن استفاده میکنیم. برای جزئیات بیشتر از جمله نحوه استفاده از بکاندهای مختلف ذخیرهسازی (مثل SQLite یا Postgres)، به مستندات آن مراجعه کنید.
برای یک راهنمای کامل در مورد نحوه مدیریت تاریخچه پیامها، به راهنمای «How to add message history (memory)» سر بزنید.
1from typing import Sequence
2
3from langchain_core.messages import BaseMessage
4from langgraph.checkpoint.memory import MemorySaver
5from langgraph.graph import START, StateGraph
6from langgraph.graph.message import add_messages
7from typing_extensions import Annotated, TypedDict
8
9
10# We define a dict representing the state of the application.
11# This state has the same input and output keys as `rag_chain`.
12class State(TypedDict):
13 input: str
14 chat_history: Annotated[Sequence[BaseMessage], add_messages]
15 context: str
16 answer: str
17
18
19# We then define a simple node that runs the `rag_chain`.
20# The `return` values of the node update the graph state, so here we just
21# update the chat history with the input message and response.
22def call_model(state: State):
23 response = rag_chain.invoke(state)
24 return {
25 "chat_history": [
26 HumanMessage(state["input"]),
27 AIMessage(response["answer"]),
28 ],
29 "context": response["context"],
30 "answer": response["answer"],
31 }
32
33
34# Our graph consists only of one node:
35workflow = StateGraph(state_schema=State)
36workflow.add_edge(START, "model")
37workflow.add_node("model", call_model)
38
39# Finally, we compile the graph with a checkpointer object.
40# This persists the state, in this case in memory.
41memory = MemorySaver()
42app = workflow.compile(checkpointer=memory)
این برنامه بهصورت پیشفرض از چندین رشته مکالمه پشتیبانی میکند. ما یک دیکشنری پیکربندی ارائه میدهیم که شناسهای منحصر به فرد برای یک رشته مشخص میکند تا کنترل کنیم کدام رشته اجرا شود. این قابلیت به برنامه اجازه میدهد تا از تعاملات با چندین کاربر پشتیبانی کند.
1config = {"configurable": {"thread_id": "abc123"}}
2
3result = app.invoke(
4 {"input": "What is Task Decomposition?"},
5 config=config,
6)
7print(result["answer"])
1Task decomposition is the process of breaking down a complicated task into smaller, more manageable steps. Techniques like Chain of Thought (CoT) and Tree of Thoughts enhance this process by guiding models to think step by step and explore multiple reasoning possibilities. This approach helps in simplifying complex tasks and provides insight into the model's reasoning.
نحوهی کارکرد برنامه به صورت گرافیکی در زیر نمایش داده شده است:
عامل یا Agent
#
عامل ها (Agents) از قابلیتهای استدلالی مدلهای زبانی بزرگ (LLMs) برای تصمیمگیری در زمان اجرا استفاده میکنند. استفاده از عوامل به شما اجازه میدهد تا بخشی از تصمیمگیری در فرآیند بازیابی اطلاعات را به آنها واگذار کنید. اگرچه رفتار آنها کمتر از زنجیرهها (chains) قابل پیشبینی است، اما استفاده از آنها در موارد زیر مزایایی دارد:
- عوامل به صورت مستقیم ورودی مورد نیاز برای
retrieverرا تولید میکنند، بدون اینکه لزوماً نیاز باشد ما صراحتاً در تولید زمینه (contextualization) مداخله کنیم، همانطور که در مثالهای قبل انجام دادیم. - عامل ها میتوانند چندین مرحله بازیابی اطلاعات را برای پاسخ به یک درخواست اجرا کنند، یا حتی از اجرای مرحله بازیابی صرفنظر کنند (برای مثال، در پاسخ به یک سلام ساده از کاربر).
ابزار بازیابی (Retrieval tool)
#
عامل ها میتوانند به “ابزارها” (tools) دسترسی داشته باشند و اجرای آنها را مدیریت کنند. در این مثال، ما retriever خود را به یک ابزار LangChain تبدیل میکنیم تا توسط عامل استفاده شود:
1from langchain.tools.retriever import create_retriever_tool
2
3tool = create_retriever_tool(
4 retriever,
5 "blog_post_retriever",
6 "Searches and returns excerpts from the Autonomous Agents blog post.",
7)
8tools = [tool]
9tool.invoke("task decomposition")
سازنده عامل Agent constructor
#
حالا که ابزارها و مدل زبانی بزرگ (LLM) را تعریف کردهایم، میتوانیم عامل را ایجاد کنیم. ما از LangGraph برای ساخت عامل استفاده خواهیم کرد. در حال حاضر از یک رابط کاربری سطح بالا برای ساخت عامل استفاده میکنیم، اما ویژگی جالب LangGraph این است که این رابط کاربری سطح بالا بر پایه یک API سطح پایین و قابل کنترل است، در صورتی که بخواهید منطق عامل را تغییر دهید.
1from langgraph.prebuilt import create_react_agent
2
3agent_executor = create_react_agent(llm, tools)
حالا میتوانیم آن را امتحان کنیم. توجه داشته باشید که تاکنون عامل stateless است و هنوز باید حافظه را اضافه کنیم.
1query = "What is Task Decomposition?"
2
3for event in agent_executor.stream(
4 {"messages": [HumanMessage(content=query)]},
5 stream_mode="values",
6):
7 event["messages"][-1].pretty_print()
1===== Human Message =====
2
3What is Task Decomposition?
4======= Ai Message ======
5Tool Calls:
6 blog_post_retriever (call_WKHdiejvg4In982Hr3EympuI)
7 Call ID: call_WKHdiejvg4In982Hr3EympuI
8 Args:
9 query: Task Decomposition
10====== Tool Message =====
11Name: blog_post_retriever
12
13Fig. 1. Overview of a LLM-powered autonomous agent system.
14Component One: Planning#
15A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
16Task Decomposition#
17Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.
18
19Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
20Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
21
22(3) Task execution: Expert models execute on the specific tasks and log results.
23Instruction:
24
25With the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.
26
27Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)
28The system comprises of 4 stages:
29(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.
30Instruction:
31======= Ai Message ======
32
33Task Decomposition is a process used in complex problem-solving where a larger task is broken down into smaller, more manageable sub-tasks. This approach enhances the ability of models, particularly large language models (LLMs), to handle intricate tasks by allowing them to think step by step.
34
35There are several methods for task decomposition:
36
371. **Chain of Thought (CoT)**: This technique encourages the model to articulate its reasoning process by thinking through the task in a sequential manner. It transforms a big task into smaller, manageable steps, which also provides insight into the model's thought process.
38
392. **Tree of Thoughts**: An extension of CoT, this method explores multiple reasoning possibilities at each step. It decomposes the problem into various thought steps and generates multiple thoughts for each step, creating a tree structure. The evaluation of each state can be done using breadth-first search (BFS) or depth-first search (DFS).
40
413. **Prompting Techniques**: Task decomposition can be achieved through simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" Additionally, task-specific instructions can guide the model, such as asking it to "Write a story outline" for creative tasks.
42
434. **Human Inputs**: In some cases, human guidance can be used to assist in breaking down tasks.
44
45Overall, task decomposition is a crucial component in planning and executing complex tasks, allowing for better organization and clarity in the problem-solving process.
دوباره میتوانیم از قابلیت حافظه داخلی LangGraph استفاده کنیم تا بروزرسانیهای stateful را در حافظه ذخیره کنیم.
1from langgraph.checkpoint.memory import MemorySaver
2
3memory = MemorySaver()
4
5agent_executor = create_react_agent(llm, tools, checkpointer=memory)
این تمام چیزی است که برای ساخت یک عامل RAG نیاز داریم.
توجه داشته باشید که اگر درخواستی وارد کنیم که نیاز به مرحله بازیابی اطلاعات ندارد، عامل مرحلهای برای بازیابی اجرا نمیکند:
1config = {"configurable": {"thread_id": "abc123"}}
2
3for event in agent_executor.stream(
4 {"messages": [HumanMessage(content="Hi! I'm bob")]},
5 config=config,
6 stream_mode="values",
7):
8 event["messages"][-1].pretty_print()
1===== Human Message =====
2
3Hi! I'm bob
4===== Ai Message ======
5
6Hello Bob! How can I assist you today?
علاوه بر این، اگر یک درخواست وارد کنیم که نیاز به مرحله بازیابی اطلاعات دارد، عامل ورودی مورد نیاز برای ابزار را تولید میکند:
1query = "What is Task Decomposition?"
2
3for event in agent_executor.stream(
4 {"messages": [HumanMessage(content=query)]},
5 config=config,
6 stream_mode="values",
7):
8 event["messages"][-1].pretty_print()
1===== Human Message =====
2
3What is Task Decomposition?
4===== Ai Message ======
5Tool Calls:
6 blog_post_retriever (call_0rhrUJiHkoOQxwqCpKTkSkiu)
7 Call ID: call_0rhrUJiHkoOQxwqCpKTkSkiu
8 Args:
9 query: Task Decomposition
10===== Tool Message =====
11Name: blog_post_retriever
12
13Fig. 1. Overview of a LLM-powered autonomous agent system.
14Component One: Planning#
15A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
16Task Decomposition#
17Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.
18
19Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
20Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
21
22(3) Task execution: Expert models execute on the specific tasks and log results.
23Instruction:
24
25With the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.
26
27Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)
28The system comprises of 4 stages:
29(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.
30Instruction:
31===== Ai Message ======
32
33Task Decomposition is a technique used to break down complex tasks into smaller, more manageable steps. This approach is particularly useful in the context of autonomous agents and large language models (LLMs). Here are some key points about Task Decomposition:
34
351. **Chain of Thought (CoT)**: This is a prompting technique that encourages the model to "think step by step." By doing so, it can utilize more computational resources to decompose difficult tasks into simpler ones, making them easier to handle.
36
372. **Tree of Thoughts**: An extension of CoT, this method explores multiple reasoning possibilities at each step. It decomposes a problem into various thought steps and generates multiple thoughts for each step, creating a tree structure. This can be evaluated using search methods like breadth-first search (BFS) or depth-first search (DFS).
38
393. **Methods of Decomposition**: Task decomposition can be achieved through:
40 - Simple prompting (e.g., asking for steps to achieve a goal).
41 - Task-specific instructions (e.g., requesting a story outline for writing).
42 - Human inputs to guide the decomposition process.
43
444. **Execution**: After decomposition, expert models execute the specific tasks and log the results, allowing for a structured approach to complex problem-solving.
45
46Overall, Task Decomposition enhances the model's ability to tackle intricate tasks by breaking them down into simpler, actionable components.
در مثال بالا، به جای اینکه درخواست خود را به همان شکلی که هست به tools وارد کند، عامل کلماتی غیرضروری مثل “چیست” و “چه” را حذف کرد.
همین اصل به عامل اجازه میدهد که در صورت لزوم از زمینه مکالمه برای تصمیمگیری استفاده کند:
1query = "What according to the blog post are common ways of doing it? redo the search"
2
3for event in agent_executor.stream(
4 {"messages": [HumanMessage(content=query)]},
5 config=config,
6 stream_mode="values",
7):
8 event["messages"][-1].pretty_print()
توجه کنید که عامل توانست تشخیص دهد که “آن” در درخواست ما به “تقسیم وظایف” اشاره دارد و در نتیجه یک پرسش جستجوی منطقی٬ در این مثال “روشهای رایج تقسیم وظایف” ایجاد کرد.