با استفاده از اندپوینت v1/fine_tuning/jobs شما قادر به تنظیم دقیق یا fine-tune کردن یک مدل٬ پیگیری وضعیت آن٬ و ارزیابی نتیجه فرایند تنظیم دقیق مدل هستید.
تنظیم دقیق (fine-tuning) به شما این امکان را میدهد که مدلهای ارائه شده توسط API را برای کارهای خاصی که مدل در انجام آنها خیلی خوب نیست آموزش دهید. مزایای این کار شامل:
- کیفیت بالاتر نسبت به جاسازی چند نمونه در
prompt - امکان آموزش با نمونههای بیشتری نسبت به آنچه که در یک
promptجا میشود - کاهش تعداد توکنهای استفاده شده به دلیل کوتاهتر شدن
promptها - کاهش تأخیر در پردازش درخواستها
مدلهای تولید متن بر روی حجم عظیمی از متون پیشآموزش دیدهاند. برای استفاده مؤثر از این مدلها، ما معمولاً دستورالعملهایی به همراه چند نمونه در یک prompt ارائه میدهیم. استفاده از نمونهها برای نشان دادن چگونگی انجام یک وظیفه معمولاً به نام “یادگیری چند-نمونهای” (few-shot learning) شناخته میشود.
fine-tuning این روش را با آموزش بر روی تعداد بسیار بیشتری از نمونهها بهبود میبخشد، که به شما امکان میدهد نتایج بهتری در طیف وسیعی از وظایف به دست آورید. پس از fine-tuning یک مدل، دیگر نیازی به ارائه تعداد زیادی نمونه در prompt ندارید. این امر موجب صرفهجویی در هزینهها و کاهش تأخیر درخواستها میشود.
مراحل کلی fine-tuning:
- آمادهسازی و بارگذاری دادههای آموزشی
- آموزش مدل
- ارزیابی نتایج و بازگشت به مرحله ۱ در صورت نیاز
- استفاده از مدل تنظیمشده
برای اطلاعات بیشتر در مورد نحوه محاسبه هزینههای آموزش به صفحه هزینهها مراجعه کنید.
کدام مدلها قابل fine-tuning هستند؟ #
در حال حاضر، fine-tuning برای مدلهای زیر در دسترس است:
gpt-4ogpt-4o-minigpt-3.5-turbo
شما همچنین میتوانید یک مدل تنظیمشده را دوباره تنظیم کنید، که در صورتی که دادههای جدیدی دریافت کنید و نخواهید مراحل قبلی را تکرار کنید، مفید است.
ما انتظار داریم که مدل gpt-4o-mini از نظر عملکرد، هزینه و سهولت استفاده برای اکثر کاربران مناسب باشد.
ساخت فرایند کار fine_tuning #
1POST https://api.gilas.io/v1/fine_tuning/jobs
با استفاده از این API فرآیند ایجاد یک کار fine-tuning ایجاد میشود که از طریق آن یک مدل جدید از یک مجموعه داده مشخص ساخته میشود.
پاسخ شامل جزئیات مربوط به وضعیت کار و نام مدلهای fine-tuned شده پس از اتمام فرآیند است.
نمونه کد زیر ساخت فرایند کار fine_tuning را نشان میدهد.
خروجی
1{
2 "object": "fine_tuning.job",
3 "id": "ftjob-abc123",
4 "model": "gpt-4o-mini",
5 "created_at": 1721764800,
6 "fine_tuned_model": null,
7 "result_files": [],
8 "status": "queued",
9 "validation_file": null,
10 "training_file": "file-abc123",
11}
بدنه درخواست (Request body) #
Required string model
نام مدلی که قصد دارید fine-tune کنید. میتوانید یکی از مدلهای پشتیبانیشده را انتخاب کنید.
Required string training_file
شناسه (ID) یک فایل آپلود شده که شامل دادههای آموزشی است.
برای اطلاعات بیشتر در مورد نحوه آپلود فایل، به بخش /v1/files مراجعه کنید. دادههای شما باید به فرمت JSONL باشد. همچنین، فایل خود را با هدف fine-tune آپلود کنید. محتوای فایل بسته به اینکه مدل از فرمت chat یا completions استفاده میکند، متفاوت خواهد بود.
برای اطلاعات بیشتر در مورد نحوه آماده سازی فایل آموزشی به آمادهسازی مجموعه داده مراجعه کنید.
object hyperparameters
پارامترهای کنترلی که برای فرآیند fine-tuning استفاده میشوند.
string batch_size یا integer پیشفرض: auto
تعداد نمونهها در هر batch. اندازهی بزرگتر batch به معنای آن است که پارامترهای مدل کمتر بهروزرسانی میشوند، اما واریانس کمتری دارند.
string learning_rate_multiplier یا number پیشفرض: auto
ضریب مقیاسدهی برای نرخ یادگیری (learning rate). نرخ یادگیری کوچکتر میتواند مفید باشد برای جلوگیری از overfitting.
string n_epochs یا integer پیشفرض: auto
تعداد epochهایی که مدل برای آنها آموزش داده میشود. یک epoch به یک چرخه کامل در دیتاست آموزشی اشاره دارد.
string suffix پیشفرض null
یک رشته تا حداکثر 64 کاراکتر که به نام مدل fine-tuned شما اضافه میشود.
برای مثال، یک suffix با مقدار "custom-model-name" نام مدلی مانند ft:gpt-4o-mini:custom-model-name:7p4lURel تولید خواهد کرد.
string validation_file
شناسه (ID) یک فایل آپلود شده که شامل دادههای ارزیابی (validation) است.
اگر این فایل را ارائه دهید، دادهها به صورت دورهای برای تولید متریکهای ارزیابی در طول فرآیند fine-tuning استفاده میشوند. این متریکها در فایل نتایج fine-tuning قابل مشاهده هستند. دادههای مشابه نباید همزمان در فایلهای آموزشی و ارزیابی قرار داشته باشند.
دادههای شما باید به فرمت JSONL باشد. شما باید فایل خود را با هدف fine-tune آپلود کنید.
integer seed
مقدار seed کنترلکننده قابلیت تکرارپذیری فرآیند است. استفاده از همان seed و پارامترهای یکسان باید نتایج مشابهی تولید کند، اگرچه در موارد نادر ممکن است متفاوت باشد. اگر seed مشخص نشود، یکی برای شما تولید خواهد شد.
لیست کردن کارهای fine_tuning #
1GET https://api.gilas.io/v1/fine_tuning/jobs
لیست کارهای تولید شدهی شما.
خروجی
1{
2 "object": "list",
3 "data": [
4 {
5 "object": "fine_tuning.job.event",
6 "id": "ft-event-TjX0lMfOniCZX64t9PUQT5hn",
7 "created_at": 1689813489,
8 "level": "warn",
9 "message": "Fine tuning process stopping due to job cancellation",
10 "data": null,
11 "type": "message"
12 },
13 { ... },
14 { ... }
15 ], "has_more": true
16}
پارامترهای مسیر (Path parameters) #
Required string fine_tuning_job_id
شماره آیدی کار مورد نظر.
پارامترهای پرسوجو (Query parameters) #
string after
تعیین نقطه شروع برای بازیابی کارها.
integer limit
تعیین تعداد کارهایی که باید بازیابی شوند.
لیست کردن event های یک کار fine_tuning #
1GET https://api.gilas.io/v1/fine_tuning/jobs/{fine_tuning_job_id}/events
نمایش آپدیت وضعیت کار.
خروجی
1{
2 "object": "list",
3 "data": [
4 {
5 "object": "fine_tuning.job.event",
6 "id": "ft-event-ddTJfwuMVpfLXseO0Am0Gqjm",
7 "created_at": 1721764800,
8 "level": "info",
9 "message": "Fine tuning job successfully completed",
10 "data": null,
11 "type": "message"
12 },
13 { ... },
14 { ... },
15 ],
16 "has_more": true
17}
پارامترهای مسیر (Path parameters) #
Required string fine_tuning_job_id
شماره آیدی کار مورد نظر.
پارامترهای پرسوجو (Query parameters) #
string after
تعیین نقطه شروع برای بازیابی eventها.
integer limit
تعیین تعداد eventهایی که باید بازیابی شوند.
لیست کردن checkpoint های یک کار fine_tuning #
1GET https://api.gilas.io/v1/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints
نمایش checkpoint های یک کار.
خروجی
1{
2 "object": "list"
3 "data": [
4 {
5 "object": "fine_tuning.job.checkpoint",
6 "id": "ftckpt_zc4Q7MP6XxulcVzj4MZdwsAB",
7 "created_at": 1721764867,
8 "fine_tuned_model_checkpoint": "ft:gpt-4o-mini-2024-07-18:custom-suffix:96olL566:ckpt-step-2000",
9 "metrics": {
10 "full_valid_loss": 0.134,
11 "full_valid_mean_token_accuracy": 0.874
12 },
13 "fine_tuning_job_id": "ftjob-abc123",
14 "step_number": 2000,
15 },
16 { ... },
17 ],
18 "first_id": "ftckpt_zc4Q7MP6XxulcVzj4MZdwsAB",
19 "last_id": "ftckpt_enQCFmOTGj3syEpYVhBRLTSy",
20 "has_more": true
21}
پارامترهای مسیر (Path parameters) #
Required string fine_tuning_job_id
شماره آیدی کار مورد نظر.
پارامترهای پرسوجو (Query parameters) #
string after
تعیین نقطه شروع برای بازیابی checkpointها.
integer limit
تعیین تعداد checkpointهایی که باید بازیابی شوند.
بازیابی یک کار fine_tuning #
1GET https://api.gilas.io/v1/fine_tuning/jobs/{fine_tuning_job_id}
دریافت اطلاعات مربوط به یک کار fine_tuning
خروجی
1{
2 "object": "fine_tuning.job",
3 "id": "ftjob-abc123",
4 "model": "gpt-4o-mini",
5 "created_at": 1692661014,
6 "finished_at": 1692661190,
7 "fine_tuned_model": "ft:gpt-4o-mini:custom_suffix:7q8mpxmy",
8 "organization_id": "org-123",
9 "result_files": [
10 "file-abc123"
11 ],
12 "status": "succeeded",
13 "validation_file": null,
14 "training_file": "file-abc123",
15 "hyperparameters": {
16 "n_epochs": 4,
17 "batch_size": 1,
18 "learning_rate_multiplier": 1.0
19 },
20 "trained_tokens": 5768,
21 "seed": 0,
22 "estimated_finish": 0
23}
پارامترهای مسیر (Path parameters) #
Required string fine_tuning_job_id
شماره آیدی کار مورد نظر.
چه زمانی یک مدل را fine-tune کنیم؟ #
تنظیم دقیق یا fine-tuning مدلهای تولید متن میتواند آنها را برای کاربردهای خاص بهتر کند، اما نیاز به سرمایهگذاری دقیق زمانی و تلاشی دارد. ابتدا توصیه میکنیم سعی کنید با استفاده از مهندسی prompt، زنجیرهبندی promptها (شکستن وظایف پیچیده به چند prompt)، و استفاده از فراخوانی توابع، نتایج خوبی بگیرید. دلایل این توصیه عبارتند از:
- بسیاری از وظایف ممکن است در ابتدا عملکرد ضعیفی داشته باشند، اما با
promptمناسب میتوان نتایج را بهبود بخشید و نیازی به fine-tuning نخواهد بود. - تکرار بر روی
promptها و تاکتیکهای دیگر بازخورد بسیار سریعتری نسبت به fine-tuning ارائه میدهد که نیاز به ایجاد مجموعه داده و اجرای کارهای آموزشی دارد. - در مواردی که fine-tuning همچنان لازم است، کار اولیه بر روی
promptبه هدر نمیرود و معمولاً بهترین نتایج زمانی به دست میآید که از یکpromptخوب در دادههای fine-tuning استفاده کنید (یا ترکیب زنجیرهبندیprompt/استفاده از ابزارها با fine-tuning).
برای آشنایی با مهندسی پرامپت یا prompt engineering پیشنهاد میدهیم دوره آموزش مهندسی پرامپت را تماشا کنید.
موارد استفاده رایج
برخی از موارد استفاده رایج که در آنها fine-tuning میتواند نتایج را بهبود بخشد:
- تعیین سبک، لحن، قالب، یا سایر جنبههای کیفی
- بهبود اطمینان در تولید خروجی دلخواه
- اصلاح ناتوانی در پیروی از
promptهای پیچیده - رسیدگی به بسیاری از موارد خاص با روشهای خاص
- انجام مهارت یا وظیفهای جدید که بیان آن در یک
promptدشوار است
یک روش سطح بالا برای درک این موارد زمانی است که “نمایش دادن” آسانتر از “گفتن” باشد. در بخشهای بعدی، نحوه تنظیم دادهها برای fine-tuning و مثالهای مختلفی که در آنها fine-tuning عملکرد مدل پایه را بهبود میبخشد، بررسی خواهد شد.
سناریوی دیگری که در آن fine-tuning مؤثر است، کاهش هزینه و/یا تأخیر است، با جایگزینی مدلهای گرانتر مانند gpt-4o با یک مدل تنظیمشده مثل gpt-4o-mini. اگر بتوانید نتایج خوبی با gpt-4o به دست آورید، معمولاً میتوانید با fine-tuning مدل gpt-4o-mini به نتایج مشابهی برسید.
آمادهسازی مجموعه داده #
پس از آن که تشخیص دادید fine-tuning راهحل مناسبی است (یعنی prompt خود را تا حد ممکن بهینه کردهاید و مشکلاتی که مدل همچنان دارد را شناسایی کردهاید)، باید دادههای آموزشی برای آموزش مدل را آماده کنید. شما باید یک مجموعه متنوع از مکالمات نمایشی که شبیه مکالماتی هستند که مدل باید در زمان تولید پاسخ دهد، ایجاد کنید.
هر نمونه در مجموعه داده باید یک مکالمه با همان قالب Chat Completions باشد، به ویژه یک لیست از پیامها که هر پیام شامل نقش، محتوا و نام اختیاری است. حداقل برخی از نمونههای آموزشی باید به طور مستقیم به مواردی که مدل prompt شده رفتار دلخواه ندارد، هدف قرار گیرند، و پیامهای assistant در داده باید پاسخهای ایدهآلی باشند که میخواهید مدل ارائه دهد.
قالب مثال
در این مثال، هدف ما ایجاد یک چتبات است که گهگاهی پاسخهای کنایهآمیز ارائه دهد. این سه نمونه آموزشی (مکالمات) میتواند برای یک مجموعه داده ایجاد شود:
1{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
2{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
3{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
مثالهای چت چند مرحلهای
نمونهها در قالب چت میتوانند شامل چندین پیام با نقش assistant باشند. رفتار پیشفرض در هنگام تنظیم دقیق، آموزش بر روی تمام پیامهای assistant در یک نمونه است. برای جلوگیری از تنظیم دقیق بر روی پیامهای خاص assistant، میتوان از کلید weight استفاده کرد که به شما اجازه میدهد کنترل کنید کدام پیامهای assistant آموزش داده شوند. مقدارهای مجاز برای weight در حال حاضر 0 یا 1 است. برخی نمونهها با استفاده از weight برای قالب چت در زیر آورده شدهاند.
1{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
2{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
3{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
ساخت prompt
ما به طور کلی توصیه میکنیم مجموعه دستورالعملها و promptهایی که پیش از تنظیم دقیق برای مدل کار کردهاند را بگیرید و آنها را در هر نمونه آموزشی بگنجانید. این باید به شما کمک کند تا به بهترین و عمومیترین نتایج برسید، به ویژه اگر تعداد نسبتاً کمی (مثلاً کمتر از صد) نمونه آموزشی دارید.
اگر میخواهید دستورالعملها یا promptهایی که در هر مثال تکرار میشوند را برای صرفهجویی در هزینهها کوتاه کنید، در نظر داشته باشید که مدل احتمالاً مانند این است که آن دستورالعملها گنجانده شدهاند و ممکن است در زمان اجرای مدل سخت باشد که مدل آن دستورالعملها را نادیده بگیرد.
ممکن است برای رسیدن به نتایج خوب نیاز به تعداد بیشتری مثال آموزشی داشته باشید، زیرا مدل باید به طور کامل از طریق نمایش یاد بگیرد و بدون راهنمایی دستورالعملها آموزش ببیند.
توصیهها در مورد تعداد مثالها
برای تنظیم دقیق یک مدل، شما باید حداقل ۱۰ مثال ارائه دهید. معمولاً بهبودهای واضحی از تنظیم دقیق بر روی ۵۰ تا ۱۰۰ مثال آموزشی با مدلهای gpt-4o-mini و gpt-3.5-turbo مشاهده میشود، اما تعداد دقیق مثالها به مورد استفاده بستگی دارد.
ما توصیه میکنیم با ۵۰ نمونه آموزشی دقیق شروع کنید و ببینید آیا مدل پس از تنظیم دقیق نشانههای بهبود نشان میدهد یا خیر. در برخی موارد این ممکن است کافی باشد، اما حتی اگر مدل هنوز به کیفیت تولیدی نرسیده باشد، بهبودهای واضح نشانه خوبی است که افزودن دادههای بیشتر به بهبود ادامه خواهد داد. عدم بهبود نشان میدهد که ممکن است نیاز به بازنگری در نحوه تنظیم وظیفه برای مدل یا ساختاردهی مجدد دادهها قبل از افزایش تعداد مثالها باشد.
برآورد هزینهها
برای اطلاع دقیق از هزینههای آموزش و هزینههای ورودی و خروجی برای یک مدل تنظیمشده، به صفحه هزینهها مراجعه کنید. توجه داشته باشید که هزینهای برای توکنهایی که برای اعتبارسنجی آموزش استفاده میشوند دریافت نمیشود. برای تخمین هزینه یک کار تنظیم دقیق خاص، از فرمول زیر استفاده کنید:
(base training cost per 1M input tokens ÷ 1M) × number of tokens in the input file × number of epochs trained
برای یک فایل آموزشی با 100,000 توکن که در طول 3 دوره آموزش داده میشود، هزینه مورد انتظار به این صورت خواهد بود:
- ~$2.70 USD با
gpt-4o-mini-2024-07-18 - ~$7.20 USD با
gpt-3.5-turbo-0125.
بارگذاری فایل آموزشی
پس از اینکه دادههای خود را اعتبارسنجی کردید، فایل باید با استفاده از API فایل بارگذاری شود تا برای کارهای تنظیم دقیق استفاده شود:
1curl https://api.gilas.io/v1/files \
2 -H "Authorization: Bearer $GILAS_API_KEY" \
3 -F purpose="fine-tune" \
4 -F file="@mydata.jsonl"
پس از بارگذاری فایل، ممکن است پردازش آن مدتی طول بکشد. در حالی که فایل در حال پردازش است، شما همچنان میتوانید یک درخواست شروع fine-tuning ایجاد کنید، اما این کار تا زمانی که پردازش فایل به پایان برسد شروع نمیشود.
حداکثر اندازه فایل بارگذاری شده ۲۵ گیگابایت است، اما توصیه نمیکنیم از این مقدار داده برای تنظیم دقیق استفاده کنید زیرا بعید است که به این حجم از داده برای مشاهده بهبودها نیاز داشته باشید.
استفاده از مدل تنظیمشده #
زمانی که یک کار موفقیتآمیز باشد، شما قسمت fine_tuned_model را با نام مدل در جزئیات کار دریافت خواهید کرد. حالا میتوانید این مدل را به عنوان پارامتر در API Chat Completions مشخص کنید و درخواستهایی به آن ارسال کنید.
1from openai import OpenAI
2client = OpenAI({
3 apiKey: process.env['GILAS_API_KEY'],
4 baseURL: 'https://api.gilas.io/v1/'
5});
6
7completion = client.chat.completions.create(
8 model="ft:gpt-4o-mini:custom_suffix:id",
9 messages=[
10 {"role": "system", "content": "You are a helpful assistant."},
11 {"role": "user", "content": "Hello!"}
12 ]
13)
14print(completion.choices[0].message)
میتوانید با استفاده از نام مدل تنظیمشده که به عنوان پارامتر ارسال میشود، درخواستها را شروع کنید.
ارزیابی مدل fine-tuned شده
#
متریکهای زیر که در طول فرآیند آموزش محاسبه شدهاند از طریق API ها در اخیار شما قرار میگیرند:
training loss- دقت
training token valid loss- دقت
valid token
مقادیر valid loss و دقت valid token به دو روش مختلف محاسبه میشوند: یک بار در یک مجموعه کوچک از دادهها در هر گام، و یک بار در کل مجموعه دادههای معتبر (valid split) در پایان هر دوره (epoch). متریکهای کامل valid loss و دقت کامل valid token دقیقترین معیار برای ارزیابی عملکرد کلی مدل شما هستند. این آمارها بهعنوان یک چکلیست برای بررسی روان بودن فرآیند آموزش استفاده میشوند (بهطور معمول loss باید کاهش یابد و دقت token باید افزایش یابد). در حین اجرای یک کار fine-tuning فعال، میتوانید یک event را مشاهده کنید که شامل برخی از متریکهای مفید است:
1{
2 "object": "fine_tuning.job.event",
3 "id": "ftevent-abc-123",
4 "created_at": 1693582679,
5 "level": "info",
6 "message": "Step 300/300: training loss=0.15, validation loss=0.27, full validation loss=0.40",
7 "data": {
8 "step": 300,
9 "train_loss": 0.14991648495197296,
10 "valid_loss": 0.26569826706596045,
11 "total_steps": 300,
12 "full_valid_loss": 0.4032616495084362,
13 "train_mean_token_accuracy": 0.9444444179534912,
14 "valid_mean_token_accuracy": 0.9565217391304348,
15 "full_valid_mean_token_accuracy": 0.9089635854341737
16 },
17 "type": "metrics"
18}
پس از پایان کار fine-tuning، میتوانید متریکهای مربوط به چگونگی عملکرد فرآیند آموزش را با پرسوجوی یک کار fine-tuning و استخراج شناسه فایل از result_files مشاهده کرده و سپس محتوای آن فایلها را بازیابی کنید. هر فایل نتایج CSV شامل ستونهای زیر است: step, train_loss, train_accuracy, valid_loss, و valid_mean_token_accuracy.
1step,train_loss,train_accuracy,valid_loss,valid_mean_token_accuracy
21,1.52347,0.0,,
32,0.57719,0.0,,
43,3.63525,0.0,,
54,1.72257,0.0,,
65,1.52379,0.0,,
با استفاده از کد زیر میتوانید نحوهی عملکرد مدل را بر اساس پارامترهای معرفی شده در بالا بررسی کنید.
پس از پایان یافتن آموزش مدل با استفاده از اندپوینت v1/fine_tuning/jobs/{fine_tuning_job_id} کار مربوط به آن را بازیابی کرده و در شیء پاسخ به دنبال پارامتری به نام result_files بگردید و آیدی فایل های تولید شده را در کد زیر استفاده کنید.
1import matplotlib.pyplot as plt
2from openai import OpenAI
3import base64
4import pandas as pd
5import os
6
7client = OpenAI(
8 # This is the default and can be omitted
9 api_key=os.environ.get("GILAS_API_KEY"),
10 base_url="https://api.gilas.io/v1/"
11)
12
13# Get the result file ID
14result_file_id = 'file-xxx'
15# Download the content
16content = client.files.content(result_file_id)
17# Decode the content
18decoded_content = base64.b64decode(content.text.encode("utf-8"))
19# Save to a CSV file
20with open("result.csv", "wb") as f:
21 f.write(decoded_content)
22# Read the CSV file into a pandas DataFrame
23df = pd.read_csv("result.csv")
24# Plot training loss
25plt.figure(figsize=(10, 6))
26plt.plot(df['step'], df['train_loss'], label='Training Loss')
27plt.plot(df['step'], df['valid_loss'], label='Validation Loss')
28plt.xlabel('Step')
29plt.ylabel('Loss')
30plt.title('Training and Validation Loss')
31plt.legend()
32plt.show()
33# Plot token accuracy
34plt.figure(figsize=(10, 6))
35plt.plot(df['step'], df['train_token_accuracy'], label='Training Accuracy')
36plt.plot(df['step'], df['valid_token_accuracy'], label='Validation Accuracy')
37plt.xlabel('Step')
38plt.ylabel('Token Accuracy')
39plt.title('Training and Validation Token Accuracy')
40plt.legend()
41plt.show()
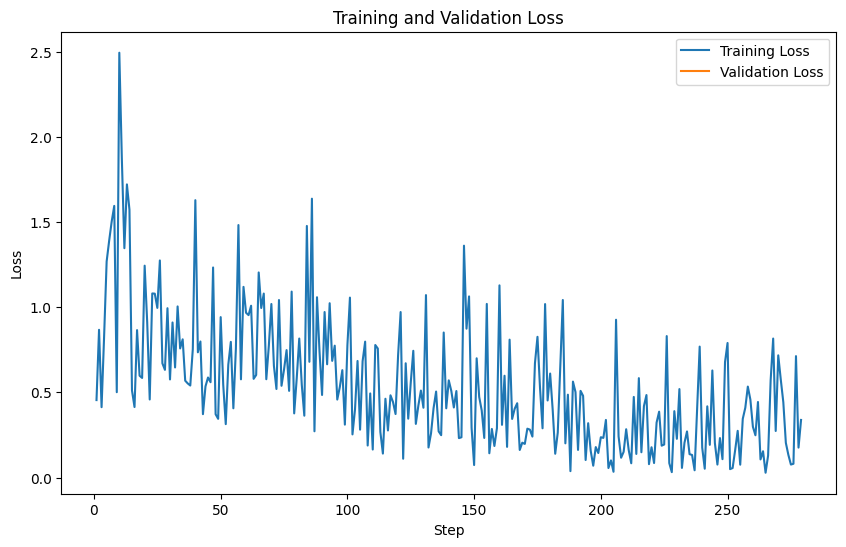
در حالی که متریکها میتوانند مفید باشند، ارزیابی نمونههایی از مدل fine-tuned بهترین حس از کیفیت مدل را ارائه میدهد. توصیه میشود که نمونههایی را از هر دو مدل پایه و مدل fine-tuned بر روی یک مجموعه تست تولید کرده و نمونهها را کنار هم مقایسه کنید. مجموعه تست باید شامل تمامی ورودیهایی باشد که ممکن است در کاربردهای تولیدی به مدل ارسال کنید. اگر ارزیابی دستی زمانبر است، میتوانید از کتابخانه Evals برای خودکارسازی ارزیابیهای آینده استفاده کنید.
بهبود کیفیت دادهها
اگر نتایج یک کار fine-tuning به اندازه انتظارتان خوب نبود، میتوانید از روشهای زیر برای بهبود مجموعه دادههای آموزشی استفاده کنید:
- جمعآوری مثالهایی برای هدفگذاری مشکلات باقیمانده
- اگر مدل هنوز در برخی جنبهها عملکرد مناسبی ندارد، مثالهای آموزشی را اضافه کنید که به طور مستقیم به مدل نشان میدهد چگونه این جنبهها را بهدرستی انجام دهد.
- بررسی دقیق مثالهای موجود برای یافتن مشکلات
- اگر مدل دارای مشکلات دستوری، منطقی یا سبکی است، بررسی کنید آیا دادههای آموزشی شما همین مشکلات را دارند. مثلاً اگر مدل به اشتباه میگوید “من این جلسه را برای شما زمانبندی میکنم”، بررسی کنید آیا مثالهای موجود به مدل آموزش دادهاند که میتواند کارهایی انجام دهد که در واقع نمیتواند.
- توجه به تعادل و تنوع دادهها
- اگر 60٪ از پاسخهای دستیار در دادهها “من نمیتوانم به این پاسخ دهم” باشد، اما در زمان اجرای مدل فقط 5٪ پاسخها باید اینگونه باشد، احتمالاً با وفور زیاد پاسخهای انکاری مواجه خواهید شد.
- مطمئن شوید که مثالهای آموزشی شما حاوی تمامی اطلاعات مورد نیاز برای پاسخدهی هستند
- مثلاً اگر میخواهید مدل بر اساس ویژگیهای شخصی کاربر به او تعریف کند و مثال آموزشی شامل تعریف از ویژگیهایی است که در مکالمه قبلی یافت نمیشوند، مدل ممکن است اطلاعات نادرست تولید کند.
- بررسی توافق و یکپارچگی در مثالهای آموزشی
- اگر چند نفر دادههای آموزشی را ایجاد کرده باشند، احتمالاً عملکرد مدل محدود به سطح توافق بین افراد خواهد بود.
- اطمینان از اینکه همه مثالهای آموزشی شما در یک فرمت مشخص و همانند فرمت مورد انتظار در زمان استنتاج هستند.
افزایش تعداد دادهها
وقتی از کیفیت و توزیع مثالها راضی شدید، میتوانید به فکر افزایش تعداد مثالهای آموزشی باشید. این امر به مدل کمک میکند تا بهتر وظیفه را یاد بگیرد، بهخصوص در موارد خاص یا edge cases. هر بار که تعداد مثالهای آموزشی خود را دو برابر کنید، انتظار بهبود مشابهی را خواهید داشت. میتوانید به صورت تقریبی میزان بهبود کیفیت را از افزایش اندازه دادههای آموزشی با روش زیر تخمین بزنید:
fine-tuningبر روی مجموعه داده فعلیfine-tuningبر روی نیمی از مجموعه داده فعلی- مشاهده تفاوت کیفیت بین دو نتیجه
بهطور کلی، اگر مجبور به انتخاب هستید، مقدار کمتری از دادههای با کیفیت بالا معمولاً مؤثرتر از مقدار زیادی دادههای با کیفیت پایین است.
بهبود hyperparameters
ما به شما امکان میدهیم تا hyperparameters زیر را تنظیم کنید:
epochslearning rate multiplierbatch size
توصیه میکنیم ابتدا بدون مشخص کردن هیچیک از این پارامترها، فرآیند آموزش را آغاز کنید و به ما اجازه دهید بر اساس اندازه مجموعه داده، مقادیر پیشفرض را برای شما انتخاب کنیم. سپس اگر موارد زیر را مشاهده کردید، آنها را تنظیم کنید:
- اگر مدل به اندازه مورد انتظار از دادههای آموزشی پیروی نمیکند، تعداد
epochsرا 1 یا 2 واحد افزایش دهید.- این بیشتر برای وظایفی شایع است که یک یا چند پاسخ ایدهآل وجود دارند، مانند طبقهبندی، استخراج موجودیت، یا پردازش ساختاری.
- اگر مدل کمتر از حد انتظار متنوع است، تعداد
epochsرا 1 یا 2 واحد کاهش دهید.- این معمولاً برای وظایفی رخ میدهد که طیف وسیعی از پاسخهای خوب وجود دارد.
- اگر مدل به نظر نمیرسد به خوبی همگرا شود، مقدار
learning rate multiplierرا افزایش دهید.
میتوانید hyperparameters را به این شکل تنظیم کنید:
1from openai import OpenAI
2client = OpenAI(
3 # This is the default and can be omitted
4 api_key=os.environ.get("GILAS_API_KEY"),
5 base_url="https://api.gilas.io/v1/"
6)
7
8client.fine_tuning.jobs.create(
9 training_file="file-abc123",
10 model="gpt-4o-mini",
11 hyperparameters={
12 "n_epochs":2
13 }
14)
توجه
در نظر داشته باشید که Gilas APIs از لحاظ فنی و نحوه کارکرد و قابلیتها کاملا شبیه OpenAI APIs هستند. به همین منظور پیشنهاد میکنیم که برای آگاهی از نحوهی کارکرد API ها به مستندات OpenAI API Reference و OpenAI Documentation ارجاع کنید.